Partitioned tables can be a quick and efficient way to (amongst other things) archive data. In the next couple of posts I will run through the basics of partitioning. Starting with setting up a partitioned table and loading some data.
Let’s create a demo database:-
USE [master];
GO
IF EXISTS(SELECT 1 FROM sys.databases WHERE name = 'DEMO')
BEGIN
DROP DATABASE [Demo];
END
CREATE DATABASE [Demo]
ON PRIMARY
(NAME = 'Demo',
FILENAME = 'C:\SQLServer\Data\Demo.MDF'),
FILEGROUP [DEMO] DEFAULT
(NAME = 'Demo_Data',
FILENAME = 'C:\SQLServer\Data\Demo_Data.NDF')
LOG ON
(NAME = 'Demo_Log',
FILENAME = 'C:\SQLServer\Logs\Demo_log.ldf')
GO
OK, so the first thing to do is create a partition function. This function defines the number of partitions we will intiailly have. It also specifies the boundaries of each partition.
USE [Demo];
GO
IF NOT EXISTS(SELECT 1 FROM sys.partition_functions WHERE name = 'DemoPartitionFunction')
CREATE PARTITION FUNCTION DemoPartitionFunction (DATE)
AS RANGE RIGHT
FOR VALUES (DATEADD(dd, DATEDIFF(dd, 0, GETUTCDATE()), 7),
DATEADD(dd, DATEDIFF(dd, 0, GETUTCDATE()), 6),
DATEADD(dd, DATEDIFF(dd, 0, GETUTCDATE()), 5),
DATEADD(dd, DATEDIFF(dd, 0, GETUTCDATE()), 4),
DATEADD(dd, DATEDIFF(dd, 0, GETUTCDATE()), 3),
DATEADD(dd, DATEDIFF(dd, 0, GETUTCDATE()), 2),
DATEADD(dd, DATEDIFF(dd, 0, GETUTCDATE()), 1),
DATEADD(dd, DATEDIFF(dd, 0, GETUTCDATE()), 0),
DATEADD(dd, DATEDIFF(dd, 0, GETUTCDATE()), -1),
DATEADD(dd, DATEDIFF(dd, 0, GETUTCDATE()), -2),
DATEADD(dd, DATEDIFF(dd, 0, GETUTCDATE()), -3),
DATEADD(dd, DATEDIFF(dd, 0, GETUTCDATE()), -4),
DATEADD(dd, DATEDIFF(dd, 0, GETUTCDATE()), -5),
DATEADD(dd, DATEDIFF(dd, 0, GETUTCDATE()), -6),
DATEADD(dd, DATEDIFF(dd, 0, GETUTCDATE()), -7));
GO
So this statement has said that my partition function is going to be using dates as boundaries. What I’ve done is setup a bunch of partitions for one week in the past and one week in the future. The function sets the right “side” of the partition as the boundary, basically specifying which side of the boundary value the partition extends. The best way of thinking about it is like this…..
Today’s date is 2014-06-04. So the boundary values created by running the above script are:-
1. 2014-05-28
2. 2014-05-29
3. 2014-05-30
4. 2014-05-31
5. 2014-06-01
6. 2014-06-02
7. 2014-06-03
8. 2014-06-04
9. 2014-06-05
10. 2014-06-06
11. 2014-06-07
12. 2014-06-08
13. 2014-06-09
14. 2014-06-10
15. 2014-06-11
Say x is a value in the table then the partitions would evaluate as:-
1. 2014-05-28 > x
2. 2014-05-28 <= x < 2014-05-29
3. 2014-05-29 <= x < 2014-05-30
4. 2014-05-30 <= x < 2014-05-31
5. 2014-05-31 <= x < 2014-06-01
6. 2014-06-01 <= x < 2014-06-02
7. 2014-06-02 <= x < 2014-06-03
8. 2014-06-03 <= x < 2014-06-04
9. 2014-06-04 <= x < 2014-06-05
10. 2014-06-05 <= x < 2014-06-06
11. 2014-06-06 <= x < 2014-06-07
12. 2014-06-07 <= x < 2014-06-08
13. 2014-06-08 <= x < 2014-06-09
14. 2014-06-09 <= x < 2014-06-10
15. 2014-06-10 <= x < 2014-06-11
16. 2014-06-11 <= x
So in these partitions, the data in the partition is always less than the value of that partition’s boundary.
After the partition function, a partition scheme needs to be created:-
IF NOT EXISTS(SELECT 1 FROM sys.partition_schemes WHERE name = 'DemoPartitionScheme')
CREATE PARTITION SCHEME DemoPartitionScheme
AS PARTITION DemoPartitionFunction
ALL TO (DEMO);
The partition scheme maps the data to a partition function and specifies where the data is going to be stored. The [ALL TO (DEMO)] part of the statement says that all partitions are going to be mapped to the DEMO filegroup.
Now that the function and scheme have been created we can create a table on the partitions:-
CREATE TABLE dbo.[DemoPartitionedTable]
(DemoID INT IDENTITY(1,1),
SomeData SYSNAME,
CaptureDate DATE,
CONSTRAINT [PK_DemoPartitionedTable] PRIMARY KEY CLUSTERED
(DemoID ASC, CaptureDate ASC)
) ON DemoPartitionScheme(CaptureDate);
Instead of specifying that the table be placed on a filegroup, the statement has [ON DemoPartitionScheme(CaptureDate)] at the end. This means that the table is on the partition scheme, using the column CaptureDate to determine which rows go on which partition.
Let’s insert some data into the table:-
INSERT INTO dbo.[DemoPartitionedTable]
(SomeData,CaptureDate)
VALUES
('Demo',DATEADD(dd, DATEDIFF(dd, 0, GETUTCDATE()), -8));
GO 457
INSERT INTO dbo.[DemoPartitionedTable]
(SomeData,CaptureDate)
VALUES
('Demo',DATEADD(dd, DATEDIFF(dd, 0, GETUTCDATE()), -7));
GO 493
INSERT INTO dbo.[DemoPartitionedTable]
(SomeData,CaptureDate)
VALUES
('Demo',DATEADD(dd, DATEDIFF(dd, 0, GETUTCDATE()), -6));
GO 486
INSERT INTO dbo.[DemoPartitionedTable]
(SomeData,CaptureDate)
VALUES
('Demo',DATEADD(dd, DATEDIFF(dd, 0, GETUTCDATE()), -5));
GO 413
INSERT INTO dbo.[DemoPartitionedTable]
(SomeData,CaptureDate)
VALUES
('Demo',DATEADD(dd, DATEDIFF(dd, 0, GETUTCDATE()), -4));
GO 473
INSERT INTO dbo.[DemoPartitionedTable]
(SomeData,CaptureDate)
VALUES
('Demo',DATEADD(dd, DATEDIFF(dd, 0, GETUTCDATE()), -3));
GO 461
INSERT INTO dbo.[DemoPartitionedTable]
(SomeData,CaptureDate)
VALUES
('Demo',DATEADD(dd, DATEDIFF(dd, 0, GETUTCDATE()), -2));
GO 422
INSERT INTO dbo.[DemoPartitionedTable]
(SomeData,CaptureDate)
VALUES
('Demo',DATEADD(dd, DATEDIFF(dd, 0, GETUTCDATE()), -1));
GO 461
INSERT INTO dbo.[DemoPartitionedTable]
(SomeData,CaptureDate)
VALUES
('Demo',DATEADD(dd, DATEDIFF(dd, 0, GETUTCDATE()),0));
GO 273
This will insert data into today’s partition and the partitions for the last 8 days. This can be checked by running the following script:-
SELECT
t.name AS TableName, i.name AS IndexName, p.partition_number,
r.value AS BoundaryValue, p.rows
FROM
sys.tables AS t
INNER JOIN
sys.indexes AS i ON t.object_id = i.object_id
INNER JOIN
sys.partitions AS p ON i.object_id = p.object_id AND i.index_id = p.index_id
INNER JOIN
sys.partition_schemes AS s ON i.data_space_id = s.data_space_id
INNER JOIN
sys.partition_functions AS f ON s.function_id = f.function_id
LEFT OUTER JOIN
sys.partition_range_values AS r ON f.function_id = r.function_id AND r.boundary_id = p.partition_number
WHERE
t.name = 'DemoPartitionedTable'
AND
i.type <= 1
ORDER BY p.partition_number;
This will show each partition and the number of rows in it:-
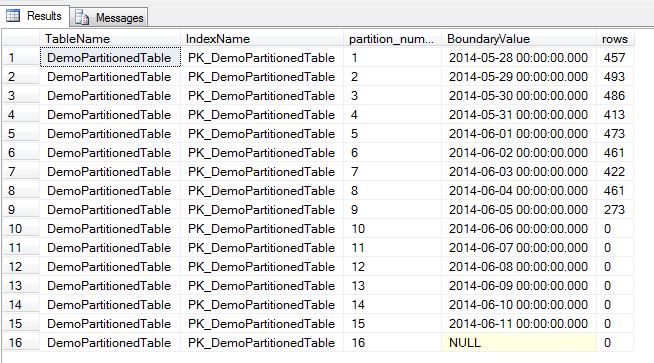
Remember that the boundary values are the upper limit, no value in the partitions will match that value due to the partition function being specified as RANGE RIGHT.
I’ll continue this post later in the month, when I’ll talk about creating new partitions and merging partitions.



