The new SQL Server 2014 feature In-Memory OLTP (code-named “Hekaton”) has been attracting a lot of interest since its release, promising to deliver (if you believe the rhetoric) an increase of up to 100 times in performance.
If you’re like me, you’ve got a copy of SQL Server 2014 Developer Edition and have played around, maybe created some memory-optimised objects but not really done much more.
But what is the real power of this feature? Why is it causing such a stir among the SQL Server community? I wanted to learn more, see what exactly In-Memory OLTP is and what it can do.
So when I saw that Red Gate were sending out copies of Kalen Delaney’s book SQL Server Internals: In-Memory OLTP for review, I jumped at the chance. I was hoping for a complete overview of the feature, specifically:-
What is In-Memory OLTP?
How does it provide the promised performance boost?
How does it differ from the existing SQL Server architecture?
How can it be applied in the “real world”?
Does the book deliver? I’ll run through each chapter, detailing what the content is and then summarise if it met my expectations.
(N.B. – The book comes with code examples, all of which can be downloaded from here. I would highly recommend that anyone reading through this book also get the code and follow along in their own instance of SQL)
The introduction to the book explains how the existing SQL Server Engine is optimised for disk based storage and why the need for In-Memory OLTP arose (aka the limitations of IO subsystems). It details the goals that the team at Microsoft were set and that In-Memory OLTP meets all of them. It then sets expectations for the book, explaining what each chapter covers and what it relates to.
I liked the way that the introduction talks about specific performance bottlenecks within SQL Server, explaining what they are, how In-Memory OLTP resolves them and in which chapter that particular feature is covered.
DBCC PINTABLE was before my time as a DBA but I have heard it being mentioned in the same breath as In-memory OLTP. The first thing this chapter 1 does is point out that the two are in no way related. In-memory OTLP is an entirely feature within the SQL Server engine, with its behaviour very different that than of the existing disk based system.
The chapter then covers objects within the new features detailing tables, indexes, stored procedures, how the promised no locking/latching access works and how In-Memory objects deal with the recovery and durability required for objects within SQL Server. Each time detailing the differences against the existing objects within SQL Server.
Each of the areas of In-Memory OLTP is broadly covered in this chapter, giving a good overview of what In-Memory OLTP is, what it can do and how it does it. If you are approaching In-Memory OLTP with no prior knowledge, this will give you a good grounding.
Chapter 2 covers creating databases that will contain memory-optimised tables, detailing the new syntax required and what limitations/restrictions there are.
Of particular interest to me was that In-Memory OLTP tables will only support indexes on character columns with a binary collation (currently). The chapter mentions setting this option at either the column or database level, the book recommends setting this at the column level.
(N.B. – This is something that I really liked about the book. All the way through it provides recommendations on the usage of In-Memory OLTP, giving sound reasoning for them).
We then get to use the first of the provided scripts, creating a database that is configured to contain memory-optimised tables and then creating the tables themselves.
The final part of the chapter talks about how to access the in-memory objects, either by standard t-sql or the new feature, natively compiled stored procedures. We are told that Chapter 7 gives a more in-depth look at natively compiled procedures but for now we are just given a brief listing some of the restrictions when querying memory optimised tables, either via t-sql or the new natively compiled stored procedures.
Chapter 3 explains how memory optimised objects are structured and how they are accessed. We are introduced to the optimistic multi-version concurrency control (MVCC) model, which uses a form of row versioning for accessing/modifying rows in memory optimised tables. This can be a little hard to follow (well it was for me at first) but the book walks us through INSERT, UPDATE and DELETE operations, step by step, detailing the work that SQL performs in the background.
This chapter shows just how differently SQL treats memory optimised tables compared to disk based tables. The book goes through these differences, explaining how SQL avoids read-write/write-write conflicts without acquiring any locks, using simple examples for clarification.
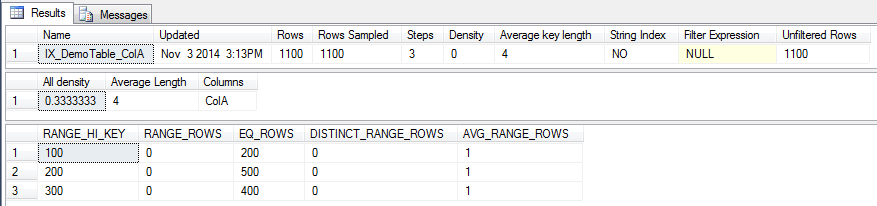
Probably the most technical chapter, chapter 4 explains the new hash and range indexes that are available for memory optimised tables.
We are taken through the new internal structures of both types of indexes, the buckets in the hash indexes and the “Bw-tree” in the range indexes. Then the book goes through how SQL performs internal index operations: consolidation, splitting and merging of pages.
The most useful section of this chapter is where it details when each type of index should be used. Hash indexes being useful for unique data being queried with equality predicates whereas range indexes used for searching for a range of values. I am intrigued with how hash indexes will perform; the book mentions that the correct number of “buckets” must be set for optimum performance but I am confused as to how this figure is to be calculated (I’m guessing trial and error).
Chapter 5 goes through how SQL Server preserves the ACID properties of every transaction against memory optimised tables. It goes through the internal processes that SQL performs for every transaction, detailing the differences in the difference isolation levels.
Of particular interest is the compatibility of the existing isolation levels with memory optimised objects. For instance READ UNCOMMITTED is not supported. What is of real benefit is the advice on when the different isolation levels that are available can be used for cross container queries (queries referencing tables on disk and in memory).
I suspect that when I come to use memory optimised tables “in anger”, I will stick to the default isolation level but having this extra information for reference is definitely useful.
There are more code examples here, allowing us to run queries in different isolation levels and observe how SQL reacts (i.e. – the errors that are generated!).
Chapter 6 explains how SQL Server supports recovery of data in memory optimised tables. It explains how SQL Server writes to the transaction log and details the concept of “reduced logging”. We are given a code example to highlight this. I really like delving into the internals of SQL Server so I thought this was great.
We are introduced to “Checkpoint File Pairs”; the book provides in-depth detail on how they are structured and how they are managed. Code is again provided so that we can observe the processes themselves, querying the relevant system objects to see what SQL is doing in the background. This is something that I’m going to explore further on my own, but it’s really helpful to have the code from the book to give me a start.
Finally the chapter details what SQL does during the recovery process, going through the checkpoint file load process and then replaying the tail of the transaction log.
Another completely new feature is the native compilation of stored procedures that can be used to access memory optimised tables. Chapter 7 explains that stored procedures can be converted to processor instructions that the server’s CPU(s) will execute directly without further compilation. This is where the performance benefit comes from; the CPU having to execute fewer instructions reduces processing time.
It also reveals that memory optimised tables are also natively compiled, so both tables and stored procedures are stored as DLLs, loaded into memory and linked to SQL Server.
The chapter then gives code examples on how to create the objects, highlighting the differences in syntax and then detailing the restrictions. The final part of the chapter, the part that I found most interesting, was focussed on performance comparisons. First we are shown details of the performance comparisons that Microsoft carried out. Then we are shown example code, allowing us to perform our own testing. I really like this, viewing performance data is one thing but being able to run scripts and see the results really drives the point home.
To complete the book, chapter 8 details how In-Memory OLTP is supported and can be managed.
We are taken through feature support, managing the memory allocations required, new reports, additions to catalog views and new dynamic management objects, best practices, current uses and finally the migration process.
The listing of the additions to the catalog views and the new dynamic management objects will be extremely useful. There is a brief summary of each but I would recommend copying out each one, finding the MSDN article and reading that in full. It’s good to know what information is available via these system objects, and the information here will allow you to build your own scripts to analyse the In-Memory OLTP architecture.
Another section that I found helpful was the section detailing current uses of In-Memory OLTP. I came away from the section already thinking about how I could apply the feature to the existing systems I manage in my day job. A little premature maybe, but for me it took In-Memory OLTP from theoretical to something that I could actually implement.
So did the book meet my expectations? Well, I started out with the questions:-
What is In-Memory OLTP?
How does it provide the promised performance boost?
How does it differ from the existing SQL Server architecture?
How can it be applied in the “real world”?
Chapter 1 gives a good overview of what In-Memory OLTP is, giving a good overview of each of the features which sets the reader up nicely for the rest of the book. How In-Memory OLTP delivers its promised performance boost and how it differs from the existing disk based architecture is mentioned throughout the book. As each feature is discussed we are told how it works and how it is different from the existing SQL Server architecture. Finally, the section in chapter 8 which talks about existing applications of In-Memory OLTP answered my final question. This was a nice touch and as I said earlier, got me thinking about how I could implement In-Memory OLTP in the system I manage.
So I have to say, yes, the book definitely met my expectations. By using an informal style (the diagrams are almost cartoonish) the book presents what could have been a very dry subject clearly, relating back to the existing architecture within SQL Server to highlight the differences and advantages of the new In-Memory OLTP features. It provides recommendations on how to implement In-Memory OLTP, providing examples of when it would and would not be useful.
The code used in each of the examples is available for download, allowing the reader to follow along and try out each of the new features. Not only does this code help explain the book subject matter but it will allow analysis of In-Memory OLTP objects when deployed in a Production environment (or at least provide a foundation for the reader to build their own custom scripts).
I would recommend this book to anyone looking to learn/implement SQL Server’s In-Memory OLTP feature.
The book can be purchased from Amazon. There will be a PDF version available in 2015 from http://www.red-gate.com/community/books/.