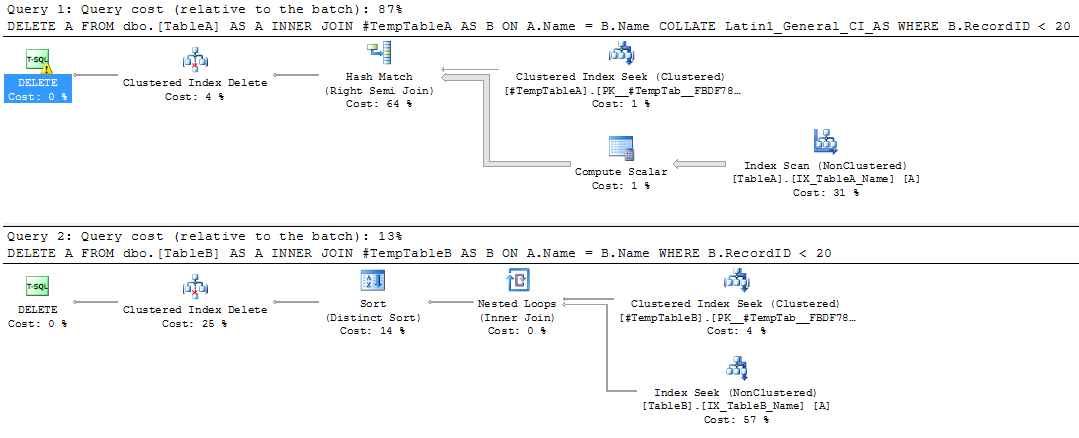
Following on from In-Memory OLTP: Part 1 – Introduction where we created a database capable of hosting memory optimised tables, I’d now like to run through the indexing options available.
As I mentioned in the last post, memory optimised tables do not have data pages. They are data rows written to memory sequentially with index pointers in the row header, meaning that it is the indexes that give order to the rows in the table. Therefore each memory optimised table must have at least one index and two new types of indexes are available.
These indexes are different from the disk based indexes that we’ve come to know and love. Each has their own internal structures which I’ll go through below.
Hash Indexes
Hash indexes are defined on Books Online as:-
A hash index consists of a collection of buckets organized in an array. A hash function maps index keys to corresponding buckets in the hash index
Confused? Yeah, me too. It helps to visualise this as:-
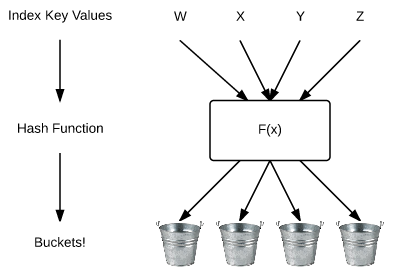
The new engine takes the value in the index and applies a hash function to map it to the internal structure (or “bucket”). We can see this by inserting records into the table created in part one and then querying a new DMV.
But first, here’s the code from part one to create the datatabase:-
USE [master];
GO
IF NOT EXISTS(SELECT 1 FROM sys.databases WHERE name = 'InMemoryOLTPDemo')
BEGIN
CREATE DATABASE [InMemoryOLTPDemo]
ON PRIMARY
(NAME = N'InMemoryOLTPDemo Primary',
FILENAME = N'C:\SQLServer\Data\InMemoryOLTPDemo.MDF',
SIZE = 5MB,
FILEGROWTH = 1MB,
MAXSIZE = UNLIMITED)
LOG ON
(NAME = 'InMemoryOLTPDemo Log',
FILENAME = N'C:\SQLServer\LogInMemoryOLTPDemo_Log.LDF',
SIZE = 5MB,
FILEGROWTH = 1MB,
MAXSIZE = UNLIMITED)
COLLATE Latin1_General_100_BIN2;
ALTER DATABASE [InMemoryOLTPDemo] ADD FILEGROUP MemData CONTAINS MEMORY_OPTIMIZED_DATA;
ALTER DATABASE [InMemoryOLTPDemo]
ADD FILE
(NAME = N'InMemoryOLTPDemo Memory Optimised',
FILENAME = N'C:\SQLServer\Data\InMemoryOLTPDemo_MemOp')
TO FILEGROUP MemData;
END
GO
Now the table can be created and records inserted:-
USE [InMemoryOLTPDemo];
GO
IF NOT EXISTS(SELECT 1 FROM sys.tables WHERE name = 'EmployeeTableInMemory')
BEGIN
CREATE TABLE [EmployeeTableInMemory]
(EmployeeID INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1024),
Department SYSNAME NOT NULL INDEX IX_Department NONCLUSTERED HASH WITH (BUCKET_COUNT = 1024),
FirstName SYSNAME,
LastName SYSNAME,
DateCreated DATE)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY);
DECLARE @Counter INT = 1;
DECLARE @Department SYSNAME;
WHILE @Counter < 1025
BEGIN
SELECT @Department =
CASE
WHEN @Counter <= 100 THEN 'IT'
WHEN @Counter > 100 AND @Counter <= 200 THEN 'HR'
WHEN @Counter > 200 AND @Counter <= 300 THEN 'Accounting'
WHEN @Counter > 300 AND @Counter <= 400 THEN 'Finance'
WHEN @Counter > 400 AND @Counter <= 500 THEN 'Marketing'
WHEN @Counter > 500 AND @Counter <= 600 THEN 'IT'
WHEN @Counter > 600 AND @Counter <= 700 THEN 'HR'
WHEN @Counter > 700 AND @Counter <= 800 THEN 'Accounting'
WHEN @Counter > 800 AND @Counter <= 900 THEN 'Finance'
WHEN @Counter > 900 AND @Counter <= 1000 THEN 'Marketing'
ELSE 'Management' END;
INSERT INTO dbo.EmployeeTableInMemory
(EmployeeID, Department, FirstName, LastName, DateCreated)
VALUES
(@Counter, @Department, 'TestForename','TestSurname',CONVERT(DATE,GETDATE()))
SET @Counter = @Counter + 1;
END
END
GO
N.B. – I’ve created two hash indexes here. One as a primary key on EmployeeID and one as a nonclustered index on Department, just so that you can see the difference in syntax.
The newly created memory optimised table now has 1024 records in it. The number of buckets used can be viewed by querying the following DMV:-
--View hash index stats
SELECT
OBJECT_NAME(h.object_id),
i.name,
h.total_bucket_count,
h.empty_bucket_count,
h.avg_chain_length,
h.max_chain_length
FROM
sys.dm_db_xtp_hash_index_stats h
INNER JOIN
sys.indexes i ON (h.object_id = i.object_id AND h.index_id = i.index_id)
WHERE
OBJECT_NAME(h.object_id) = 'EmployeeTableInMemory';
GO
Which gives the following output:-

Wait, why haven’t all the buckets been used? The indexes were created with 1024 buckets and the table had 1024 records inserted so what’s going on? Shouldn’t the PK have used all the buckets?
This happens because the hash function is balanced resulting in values not being mapped evenly to the hash buckets. Books Online advises that the distribution of values to their hash buckets usually follows a Poisson Distribution:-
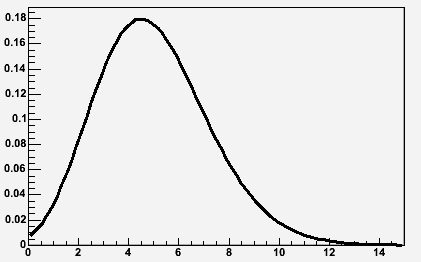
Image source:- http://root.cern.ch/root/html/TMath.html
But does that mean determining the number of buckets to use is very difficult? Remember that the index has to be created at the same time as the table and cannot be altered.
The general rule seems to be to have a bucket count that is approximately twice the number of unique records in the column it is applied to. Books Online also mentions that there should not be any noticeable performance impact if the bucket count is within five times the number of unique records.
Performance can be affected by setting an incorrect bucket count so if you cannot determine an approximate figure you should use the second type of index available on memory optimised tables, range indexes.
Range Indexes
Range indexes utilise a new structure called a Bw-tree:-
The Bw-tree Structure

Look familiar? Looks somewhat similar to a normal B-tree right? In fact a Bw-tree can be thought of as a lock/latch free version of a traditional B-tree.
This is implemented by use of a mapping table which maps physical memory locations to logical page identifers (PIDs). The PIDs are used to link the nodes in the Bw-tree which allows the physical location of a page to change on every update with the mapping table updated to the new physical location. This means that the pages are never updated, never changed, they are simply replaced for each update enabling the no locking or latching functionality.
However at the leaf level, not all updates replace a page. Instead “delta” records are created.
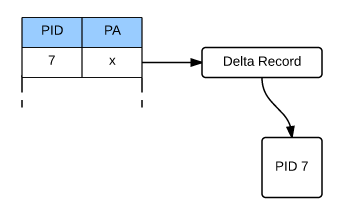
When a DML operation occurs (e.g.- delete/insert/update) a delta record describing the change is created. This delta record is then linked to the original page and the physical address of the page in the mapping table is updated to point to the delta record.
This allows a performance saving by the In-Memory OLTP engine not having to create a new page for every operation. However this does mean that when traversing down the Bw-tree, SQL will have to go through all the delta records before hitting a page. This can have a performance impact so there is a background process that routinely consolidates a page’s delta records.
Still with me? OK, let’s create a range index. It’s pretty simple to do, however again, as tables cannot be altered once created they must be created at the same time as the table:-
USE [InMemoryOLTPDemo];
GO
IF EXISTS(SELECT 1 FROM sys.tables WHERE name = 'EmployeeTableInMemory')
DROP TABLE [EmployeeTableInMemory];
GO
IF NOT EXISTS(SELECT 1 FROM sys.tables WHERE name = 'EmployeeTableInMemory')
CREATE TABLE [EmployeeTableInMemory]
(EmployeeID INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1024),
Department SYSNAME NOT NULL INDEX IX_Department NONCLUSTERED HASH WITH (BUCKET_COUNT = 1024),
FirstName SYSNAME,
LastName SYSNAME,
DateCreated DATE NOT NULL INDEX IX_DateCreated NONCLUSTERED)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY);
GO
No new DMVs for range indexes (use sys.indexes for information) the differences are the internal structure and how they’re created.
Usage
So how are these new indexes used? Well hash indexes are used for queries with equality operators, for example:-
SELECT * FROM dbo.EmployeeTableInMemory WHERE Department = 'IT' ORDER BY EmployeeID ASC; GO
Range Indexes and used for queries with inequality operators (scanning a range of values):-
SELECT * FROM dbo.EmployeeTableInMemory WHERE DateCreated >= CONVERT(DATE,'2015-03-31') AND DateCreated <= CONVERT(DATE,'2015-04-02') ORDER BY EmployeeID ASC; GO
N.B. – Have a look at the query plans generated.
Limitations
Finally as this is pretty much version 1.0 of In-Memory OLTP there are some limitations on creating indexes:-
- Character columns in the index must have a binary collation
- No clustered indexes
- Only one unique index supported (the primary key)
- Maximum of eight indexes per table
- Indexes created “in-line” with table and cannot be dropped/altered
I hope that’s been a good introduction into indexes on memory optimised tables. Thanks for reading!
Further Reading
Guidelines on using indexes on memory optimised table – Books Online
Hash indexes – Books Online
Hash indexes – Tony Rogerson
The Bw-Tree: A B-tree for New Hardware – Microsoft Research
The Bw-Tree: A B-Tree On Steroids – Justin Levandoski, David Lomet & Sudipta Sengupta