This post follows on from In-Memory OLTP: Part 2 – Indexes
So far in this blog series memory optimised tables have been created with the durability option of SCHEMA_ONLY meaning that data will not be retained. However there is another durability option of SCHEMA_AND_DATA which means that SQL will retain data held in memory optimised tables.
But how is this achieved? Well, this is done via the transaction log (the same as with disk based tables) and checkpoint file pairs which are written to by the checkpoint process. It is these CFPs that I want to go through in this post.
Checkpoint Operations
The purpose of the checkpoint operation in SQL is to reduce recovery time by hardening to disk data pages that have been altered in memory (i.e.- “dirty” pages) and as such SQL will not have to apply the corresponding redo operations from the transaction log in the event of a crash. However even though the purpose is the same for both disk based and memory optimised tables the process is different. For memory optimised tables the checkpoint process is continuous and utilises the previously mentioned checkpoint file pairs (CFPs).
Each CFP contains:-
- One data file which records INSERT operations
- One delta file which records DELETE operations
N.B. – UPDATES are recorded as INSERT & DELETE operations
To show what is meant by a continuous checkpoint let’s have a look at the process. Create a database as normal:-
USE [master];
GO
IF EXISTS(SELECT 1 FROM sys.databases WHERE name = 'InMemoryOLTPDemo')
DROP DATABASE [InMemoryOLTPDemo];
GO
IF NOT EXISTS(SELECT 1 FROM sys.databases WHERE name = 'InMemoryOLTPDemo')
BEGIN
CREATE DATABASE [InMemoryOLTPDemo]
ON PRIMARY
(NAME = N'InMemoryOLTPDemo Primary',
FILENAME = N'C:\SQLServer\Data\InMemoryOLTPDemo.MDF',
SIZE = 5MB,
FILEGROWTH = 1MB,
MAXSIZE = UNLIMITED)
LOG ON
(NAME = 'InMemoryOLTPDemo Log',
FILENAME = N'C:\SQLServer\LogInMemoryOLTPDemo_Log.LDF',
SIZE = 5MB,
FILEGROWTH = 1MB,
MAXSIZE = UNLIMITED)
COLLATE Latin1_General_100_BIN2;
END
GO
Then add the filegroup and underlying file structure for memory optimised tables:-
ALTER DATABASE [InMemoryOLTPDemo] ADD FILEGROUP MemData CONTAINS MEMORY_OPTIMIZED_DATA;
ALTER DATABASE [InMemoryOLTPDemo]
ADD FILE
(NAME = N'InMemoryOLTPDemo Memory Optimised',
FILENAME = N'C:\SQLServer\Data\InMemoryOLTPDemo_MemOp')
TO FILEGROUP MemData;
GO
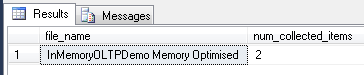
Have a look at the file system, you will see that a folder has been created at C:\SQLServer\Data\ called InMemoryOLTPDemo_MemOP:-
Drilling down into the folder, there will be two subfolders with unique identifiers for names. The lowest level folder will be empty until a memory optimised table is created:-
USE [InMemoryOLTPDemo];
GO
IF EXISTS(SELECT 1 FROM sys.tables WHERE name = 'EmployeeTableInMemory')
DROP TABLE [EmployeeTableInMemory];
GO
IF NOT EXISTS(SELECT 1 FROM sys.tables WHERE name = 'EmployeeTableInMemory')
CREATE TABLE [EmployeeTableInMemory]
(EmployeeID INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1024),
Department SYSNAME NOT NULL INDEX IX_Department NONCLUSTERED HASH WITH (BUCKET_COUNT = 1024),
FirstName SYSNAME,
LastName SYSNAME,
DateCreated DATE)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA);
GO
N.B. – Note that the durability option for this table is now set as SCHEMA_AND_DATA
Rechecking the folder, it will now have a number of files:-
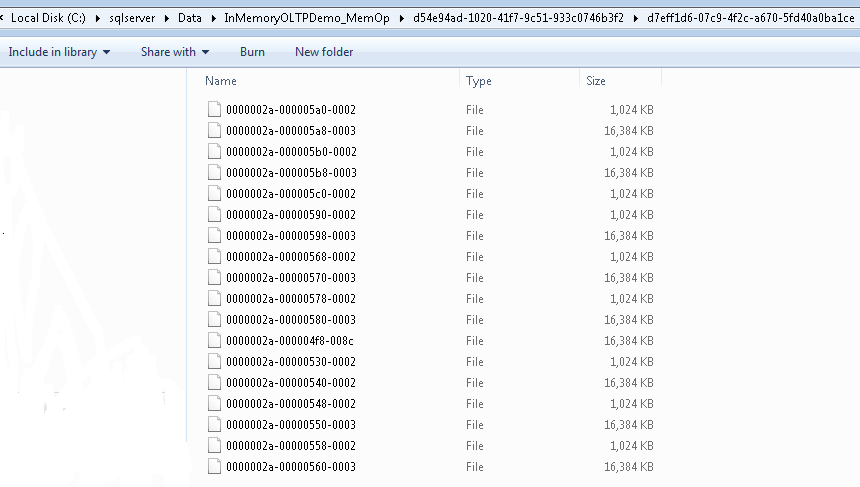
These are the physical CFPs, 18 files in total, 9 pairs.
We can get more information on these files by running the following script within SQL:-
SELECT
container_id,
internal_storage_slot,
file_type_desc,
state_desc,
inserted_row_count,
deleted_row_count,
lower_bound_tsn,
upper_bound_tsn
FROM
sys.dm_db_xtp_checkpoint_files
ORDER BY
file_type_desc,
state_desc
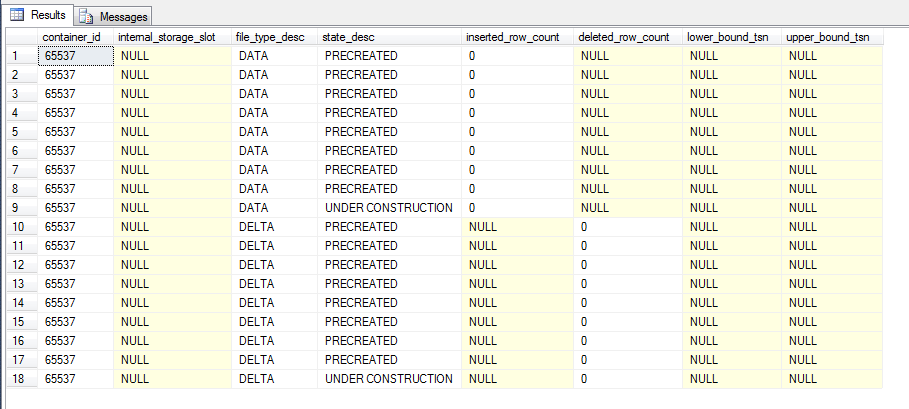
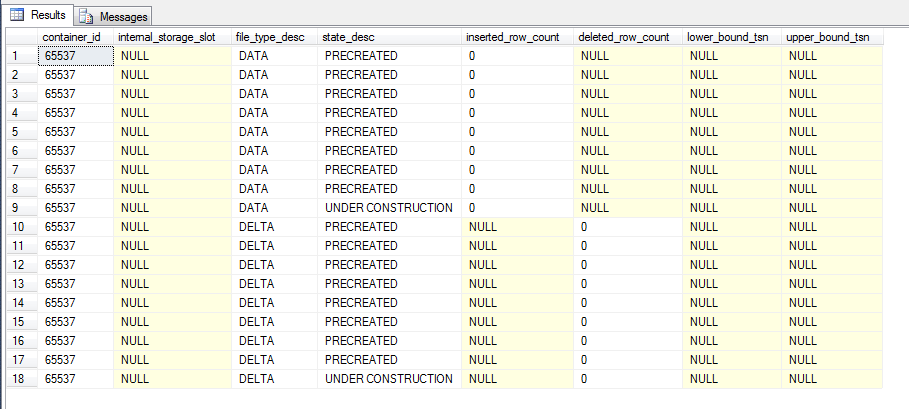
Here we can see the 9 file pairs, most of which are ready for use by being marked as PRECREATED and one pair currently ready to have records written to them by being marked as UNDER CONSTRUCTION.
We can also see the following:-
- inserted_row_count – number of records inserted into the data file
- deleted_row_count – number of records in the delta file marking records in the data file as deleted
- lower_bound_tsn – earliest transaction covered by the file
- upper_bound_tsn – latest transaction covered by the file
N.B. – For a full description of the columns contained in this DMV see here
So let’s insert and then delete some data:-
DECLARE @Counter INT = 1;
WHILE @Counter < 1000
BEGIN
INSERT INTO dbo.EmployeeTableInMemory
(EmployeeID, Department, FirstName, LastName, DateCreated)
VALUES
(@Counter, 'TEST', 'TestForename','TestSurname',CONVERT(DATE,GETDATE()))
SET @Counter = @Counter + 1;
END
GO
DELETE FROM dbo.EmployeeTableInMemory
WHERE EmployeeID < 200;
GO
Check the DMV:-
SELECT
container_id,
internal_storage_slot,
file_type_desc,
state_desc,
inserted_row_count,
deleted_row_count,
lower_bound_tsn,
upper_bound_tsn
FROM
sys.dm_db_xtp_checkpoint_files
ORDER BY
file_type_desc,
state_desc
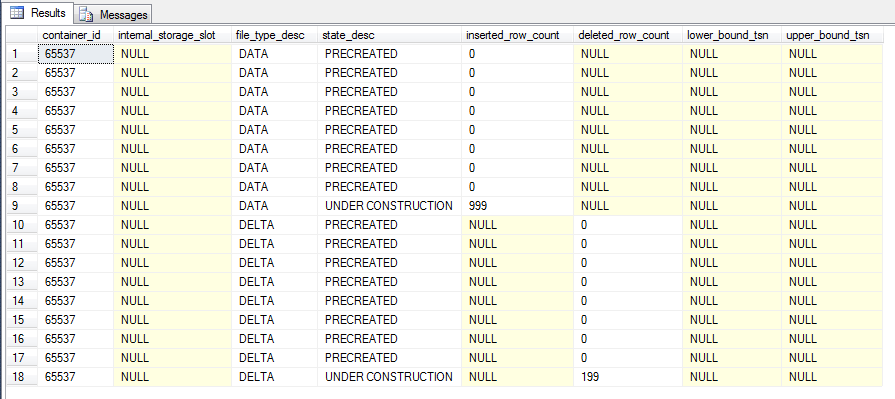
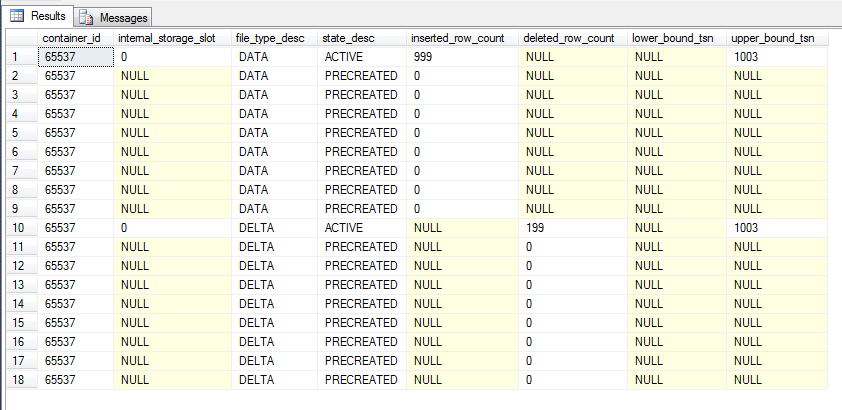
The continuous checkpoint process has written the data changes to the CFP marked as UNDER CONSTRUCTION. So what happens when a checkpoint occurs? Let’s run a manual checkpoint operation:-
CHECKPOINT
And then re-check the DMV:-
SELECT
container_id,
internal_storage_slot,
file_type_desc,
state_desc,
inserted_row_count,
deleted_row_count,
lower_bound_tsn,
upper_bound_tsn
FROM
sys.dm_db_xtp_checkpoint_files
ORDER BY
file_type_desc,
state_desc
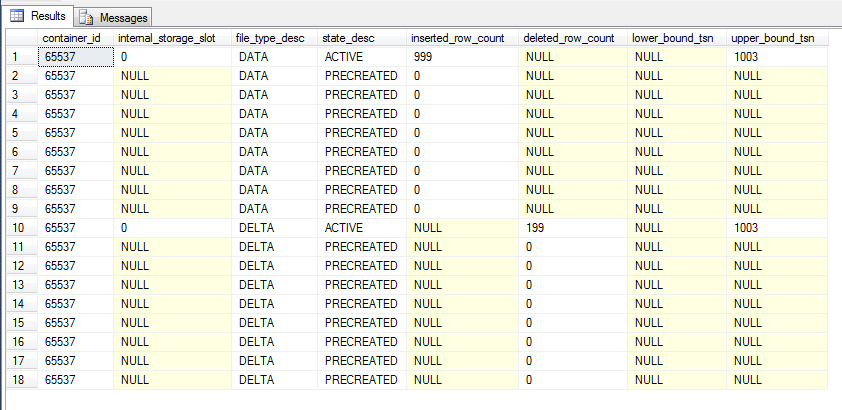
The previous files marked as “Under Construction” are now “Active”. This is the continuous checkpoint process in action, changes are written to the CFPs as they occur. When a CHECKPOINT command is issued (either by SQL or by the user manually) the current CFPs marked as UNDER CONSTRUCTION are then marked as ACTIVE. No more records will be written to the data file, although records can still be written to the delta (to mark records in the data file as deleted).
A new CFP will be created if more data is inserted into the table:-
DECLARE @Counter INT = 1000;
WHILE @Counter < 2000
BEGIN
INSERT INTO dbo.EmployeeTableInMemory
(EmployeeID, Department, FirstName, LastName, DateCreated)
VALUES
(@Counter, 'TEST', 'TestForename','TestSurname',CONVERT(DATE,GETDATE()))
SET @Counter = @Counter + 1;
END
And check the DMV again:-
SELECT
container_id,
internal_storage_slot,
file_type_desc,
state_desc,
inserted_row_count,
deleted_row_count,
lower_bound_tsn,
upper_bound_tsn
FROM
sys.dm_db_xtp_checkpoint_files
ORDER BY
file_type_desc,
state_desc
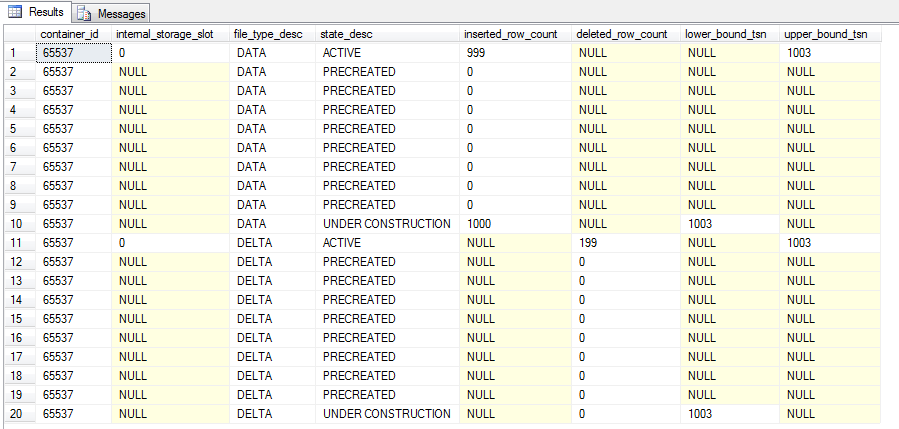
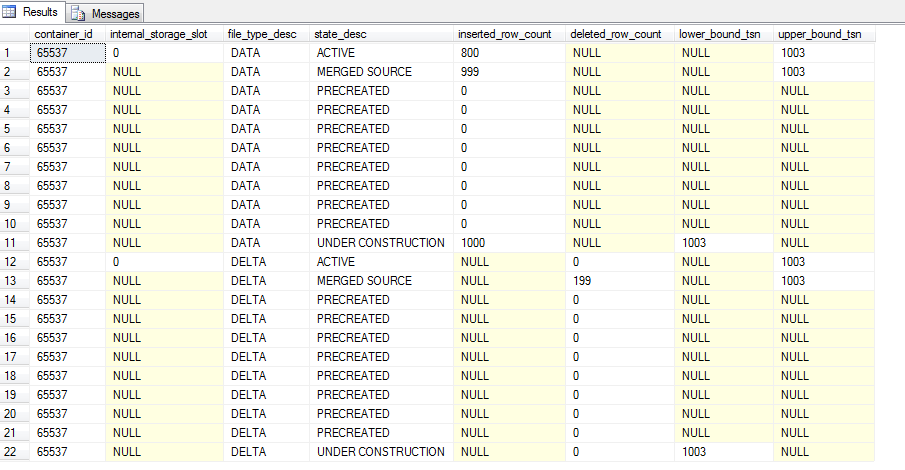
There are now 20 records in the table, the two new records representing the data and delta files of the new CFP marked as UNDER CONSTRUCTION. As you may have guessed, adding more and more CFPs can affect recovery time so a background process runs to analyse the CFPs and merge old ones when necessary (i.e.- when the data in them is no longer required). But CFPs can be merged manually by running sys.sp_xtp_merge_checkpoint_files:-
EXEC sys.sp_xtp_merge_checkpoint_files 'InMemoryOLTPDemo',1003,1003;
GO
And check the DMV one more time:-
SELECT
container_id,
internal_storage_slot,
file_type_desc,
state_desc,
inserted_row_count,
deleted_row_count,
lower_bound_tsn,
upper_bound_tsn
FROM
sys.dm_db_xtp_checkpoint_files
ORDER BY
file_type_desc,
state_desc
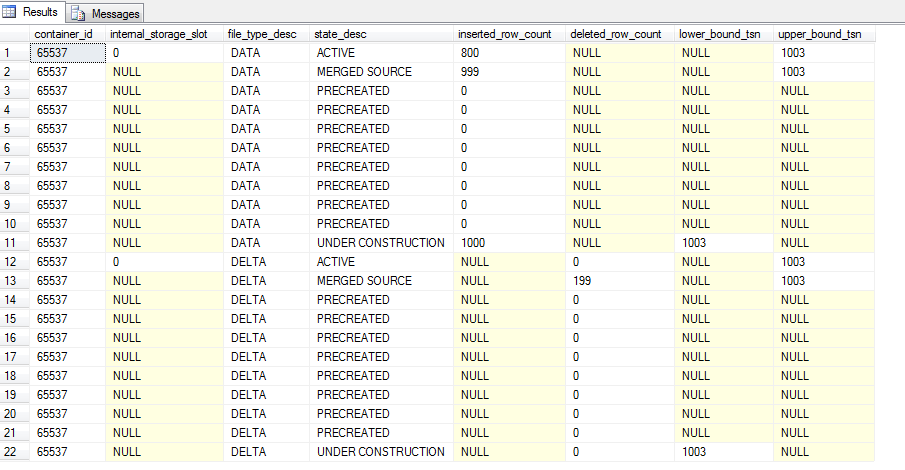
The active data file now has 800 records which is the original 999 minus the 199 from its corresponding delta file. The old CFP is now marked as MERGED SOURCE which means that a merge operation has been “installed”. This can be checked by running:-
SELECT request_state_desc, lower_bound_tsn, upper_bound_tsn
FROM sys.dm_db_xtp_merge_requests;
GO

This CFPs are no longer needed and can be removed by the background (or “garbage”) process, once:-
- A checkpoint has occurred
- A log backup has been taken
- The garbage collection process has run
This can be done manually by running:-
--Take a full backup (as we don't currently have one)
BACKUP DATABASE [InMemoryOLTPDemo]
TO DISK = N'C:\SQLServer\Backups\InMemoryOLTPDemo.BAK';
GO
And then:-
--This section may need to be run twice
CHECKPOINT;
GO
BACKUP LOG [InMemoryOLTPDemo]
TO DISK = N'C:\SQLServer\Backups\InMemoryOLTPDemo.TRN';
GO
EXEC sp_xtp_checkpoint_force_garbage_collection;
GO
CHECKPOINT;
GO
The reason the second set of code has to be run twice is that SQL will mark the merged CFPs as REQUIRED FOR BACKUP/HA as this is the first log backup we’ve taken. Running it a second time will mark them as TOMBSTONE:-

These files can now be removed by the garbage collection process, which can be replicated by running:-
CHECKPOINT;
GO
BACKUP LOG [InMemoryOLTPDemo]
TO DISK = N'C:\SQLServer\Backups\InMemoryOLTPDemo.TRN';
GO
EXEC sp_filestream_force_garbage_collection;
GO
N.B.- You should never do this on a production system, the garbage process is automatic but hey, this is a demo.
Again, this code may have to be run more than once but (eventually) you’ll see:-
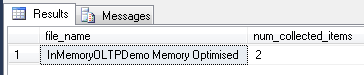
This means that two CFP files which were marked as TOMBSTONE have been removed.
Recovery
Just a final word on how the CFPs are used in the recovery process. If (when???) SQL crashes, the data and delta files are used to re-populate all memory optimised tables. The files are scanned and loaded into memory, all active rows in the data file are inserted after removal of rows in the delta file. Due to the pairing of the data & delta files the recovery process can be parallelised with multiple threads reading each pair. Once the load is complete the tail of the log is replayed to bring the database back to its state before the crash (as normal).
I hope that’s been a good overview of checkpoint file pairs for memory optimised tables. Thanks for reading!
Further Reading
Checkpoint Operation for Memory-Optimized Tables
Durability for Memory-Optimized Tables