I’ve been interested (obsessed?) with running SQL Server in containers for a while now, ever since I saw how quick and easy it was to spin one up. That interest has led me down some rabbit holes for the last few years as I’ve been digging into exactly how containers work.
The weirdest concept I had to get my head around was that containers aren’t actually a thing.
Containers are just processes running on a host that implement a set of Linux constructs in order to achieve isolation.
So if we know what constructs are used…shouldn’t we be able to build our own container from scratch?
Well as we’re about to see, yes we can! But before that…let’s briefly go over exactly how containers achieve isolation. There’s three main Linux constructs that are used: –
- Control Groups
- Namespaces
- Changing the root of the container
Ok, first one…control groups.
Control groups limit the amount of resources of the host that a container can use. So when we use the cpus or memory flags in a docker container run statement…what’s happening in the background is that control groups are created to enforce those limits.
Next one, namespaces.
If control groups control what a container can use, namespaces control what a container can see. There’s a few of them in practice but the ones I want to mention here are the obviously named Unix Timesharing Namespace and the Process ID (PID) Namespace.
The Unix Timesharing Namespace…sounds complicated but in practice all this does is allow the hostname the container sees to be different to the actual host the container is running on.
Run the following against a container: =
docker exec CONTAINERNAME hostname
You’ll see that the output is different (usually the container ID) that the actual name of the host the container is running on. This is due to the container having its own UTS namespace.
The Process ID namespace is implemented to restrict which processes the container can see.
Run this against a container: –
docker exec CONTAINERNAME ps aux
The output will only show the processes running in the container. This is due to the container having its own process ID namespace.
If you run the following on the host, you’ll see the SQL processes of the container: –
ps aux | grep mssql
So there’s the processes on the host! Different process IDs due to the container running in a process ID namespace but there they are!
Ok, final one…changing the root of the container.
Containers can’t see the whole host’s filesystem, they can only see a subset of that file system. That’s because the root of the container is changed upon start up to some location on the host…and the container can only see from that location down.
Anyway, by using control groups, namespaces, and changing the root of the container…processes are isolated on a host and boom! We have a “container”.
So, we know the constructs involved…let’s put this into practice and build our own container from scratch using Go.
Right…let’s go ahead and build a container from scratch….
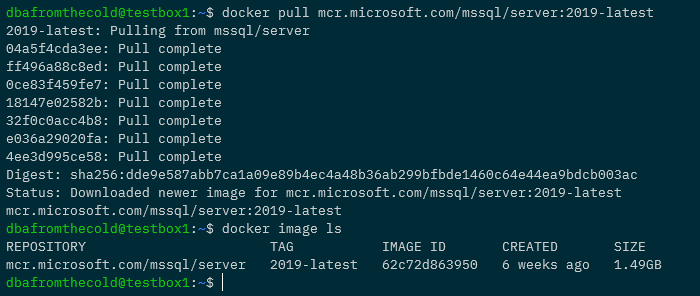
First thing we’re going to do is pull down the latest SQL Server 2019 container image. Yes I know I said we’d be building a container from scratch but bear with me 🙂
docker pull mcr.microsoft.com/mssql/server:2019-latest
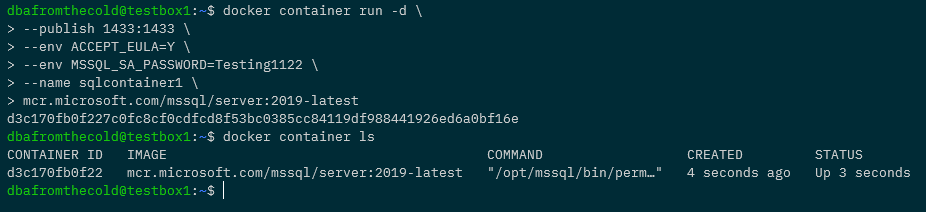
Now run a container: –
docker container run -d \
--publish 1433:1433 \
--env ACCEPT_EULA=Y \
--env MSSQL_SA_PASSWORD=Testing1122 \
--name sqlcontainer1 \
mcr.microsoft.com/mssql/server:2019-latest
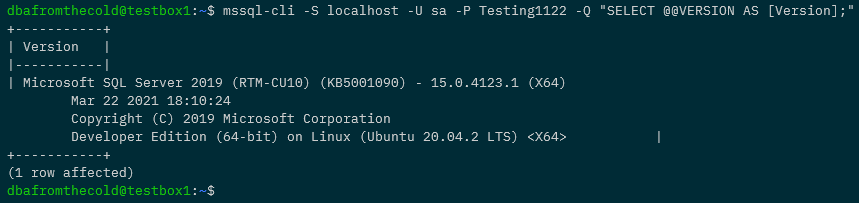
Confirm SQL is running within the container (mssql-cli can be installed using these instructions): –
mssql-cli -S localhost -U sa -P Testing1122 -Q "SELECT @@VERSION AS [Version];"
Stop the container: –
docker stop sqlcontainer1
Export the container: –
docker export sqlcontainer1 -o sqlcontainer.tar

Create a directory and extract the .tar file to it: –
mkdir sqlcontainer1
tar -xvf sqlcontainer1 -C ./sqlcontainer1
Then list the contents of the directory: –
ls ./sqlcontainer1

Cool! We have extracted the containers filesystem. So we can now use that as the root of our own container, built from scratch!
We’re going to be using Go to run our container from scratch so we’ll need to install it: –
sudo apt-get install golang-go
And now, here is the code to run our container: –
package main
import (
"fmt"
"io/ioutil"
"os"
"os/exec"
"path/filepath"
"strconv"
"syscall"
)
// go run main.go run <cmd> <args>
func main() {
switch os.Args[1] {
case "run":
run()
case "child":
child()
default:
panic("help")
}
}
func run() {
fmt.Printf("Running %v \n", os.Args[2:])
cmd := exec.Command("/proc/self/exe", append([]string{"child"}, os.Args[2:]...)...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS,
Unshareflags: syscall.CLONE_NEWNS,
}
must(cmd.Run())
}
func child() {
fmt.Printf("Running %v \n", os.Args[2:])
cg()
cmd := exec.Command(os.Args[2], os.Args[3:]...)
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
must(syscall.Sethostname([]byte("sqlcontainer1")))
must(syscall.Chroot("/home/dbafromthecold/sqlcontainer1"))
must(os.Chdir("/"))
must(syscall.Mount("proc", "proc", "proc", 0, ""))
must(cmd.Run())
must(syscall.Unmount("proc", 0))
}
func cg() {
cgroups := "/sys/fs/cgroup/"
memory := filepath.Join(cgroups, "memory")
os.Mkdir(filepath.Join(memory, "sqlcontainer1"), 0755)
must(ioutil.WriteFile(filepath.Join(memory, "sqlcontainer1/memory.limit_in_bytes"), []byte("2147483648"), 0700))
cpu := filepath.Join(cgroups, "cpu,cpuacct")
os.Mkdir(filepath.Join(cpu, "sqlcontainer1), 0755)
must(ioutil.WriteFile(filepath.Join(cpu, "sqlcontainer1/cpu.cfs_quota_us"), []byte("200000"), 0700))
// Removes the new cgroup in place after the container exits
must(ioutil.WriteFile(filepath.Join(memory, "sqlcontainer1/notify_on_release"), []byte("1"), 0700))
must(ioutil.WriteFile(filepath.Join(memory, "ssqlcontainer1/cgroup.procs"), []byte(strconv.Itoa(os.Getpid())), 0700))
must(ioutil.WriteFile(filepath.Join(cpu, "sqlcontainer1/notify_on_release"), []byte("1"), 0700))
must(ioutil.WriteFile(filepath.Join(cpu, "sqlcontainer1/cgroup.procs"), []byte(strconv.Itoa(os.Getpid())), 0700))
}
func must(err error) {
if err != nil {
panic(err)
}
}
Now, this is Liz Rice’s Containers From Scratch code, with a couple of (minor) modifications to run SQL.
I’m not going to go through what all of it does, Liz Rice does a far better job of that in her Building Containers From Scratch session. Highly recommend you check out that session.
However I do want to point a couple of things out.
Firstly here: –
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID
This is where we’re creating a new unix timesharing namespace, so the hostname within the container will be different to the actual host the container is running on. And we’re also creating a new process id namespace, so that the container can only see its own processes.
Then we’re changing the hostname the container sees to sqlcontainer1: –
must(syscall.Sethostname([]byte("sqlcontainer1")))
Then changing the root of the container to the location that we extracted the Docker container’s filesystem to: –
must(syscall.Chroot("/home/dbafromthecold/sqlcontainer1"))
Finally, creating a couple of cgroups: –
must(ioutil.WriteFile(filepath.Join(memory, "sqlcontainer1/memory.limit_in_bytes"), []byte("2147483648"), 0700))
must(ioutil.WriteFile(filepath.Join(cpu, "sqlcontainer1/cpu.cfs_quota_us"), []byte("200000"), 0700))
Here we’re creating cgroups to limit the memory available to the container to 2GB, and limiting the number of CPUs to 2.
Right, let’s pull that code down into a directory: –
mkdir container
cd container
curl https://gist.githubusercontent.com/dbafromthecold/139e93907f7eab45a20944d0eaffeb3a/raw/d1d7b71197d70755bc055b9dd06744e50916d657/main.go -o main.go

Awesome stuff, we are ready to run our container!
Switching to the root user, we can run our container and open a shell into it by running: –
sudo su
go run main.go run /bin/bash

Hmm, ok…the terminal now looks different..are we in our container?
Let’s have a look at the hostname: –
hostname
Ah ha! The hostname is set to sqlcontainer1! We are in our container!
OK, let’s spin up SQL Server within it! Firstly we need to create a special file that SQL requires to run :-
mknod -m 444 /dev/urandom c 1 9
Many thanks to Mark Wilkinson (b|t) who figured that one out!
Right, we are good to go! Let’s run SQL in the background: –
/opt/mssql/bin/sqlservr&> /dev/null &
Err, ok…has that worked? Let’s check the processes in the container: –
ps aux

Cool! We have a couple of SQL processes running! And because the container is in a process id namespace…it can only see its own processes.
If we check the processes on the host: –
ps aux | grep mssql

There they are on the host! With different process IDs because of the namespace.
OK, final thing to have a look at…the control groups. We created one for memory and CPU..so let’s have a look at them.
Running on the host (not in the container)…let’s get the memory limit: –
MEMORYLIMIT=$(cat /sys/fs/cgroup/memory/sqlcontainer1/memory.limit_in_bytes)
expr $MEMORYLIMIT / 1024 / 1024

There is the 2GB memory limit for the container being implemented by a control group!
Ok, let’s check the CPU limit: –
cat /sys/fs/cgroup/cpu,cpuacct/sqlcontainer1/cpu.cfs_quota_us

Cool! There’s the CPU limit that was set.
So by using that little piece of Go code, and some knowledge of how containers work in the background…we can spin up our own container built from scratch!
Ok, I admit…this isn’t exactly going to be as stable as running a container in Docker and there’s a few things still missing (port mapping anyone?) but I think it’s really cool to be able to do this. 🙂
Thanks for reading!