A project I’ve been meaning to work on for a while has been to build my own Kubernetes cluster running on Raspberry Pis.
I’ve been playing around with Kubernetes for a while now and things like Azure Kubernetes Service are great tools to learn but I wanted something that I’d built from the ground up.
Something that I could tear down, fiddle with, and rebuild to my heart’s content.
So earlier this year I finally got around to doing just that and with Azure SQL Edge going GA with a disconnected mode I wanted to blog about my setup.
Here’s what I bought: –
1 x Raspberry Pi 4 Model B – 8BG RAM
3 x Raspberry Pi 4 Model B – 4GB RAM
4 x SanDisk Ultra 32 GB microSDHC Memory Card
1 x Pi Rack Case for Raspberry Pi 4 Model B
1 x Aukey USB Wall Charger Adapter 6 Ports
1 x NETGEAR GS308 8-Port Gigabit Ethernet Network Switch
1 x Bunch of ethernet cables
1 x Bunch of (short) USB cables
OK, I’ve gone a little overboard with the Pis and the SD cards. You won’t need an 8GB Raspberry Pi for the control node, the 4GB model will work fine. The 2GB model will also probably work but that would be really hitting the limit.
For the SD cards, 16GB will be more than enough (I went with a 64GB card for the control node, which is definite overkill).
In fact, you could just buy one Raspberry Pi and do everything I’m going to run through here on it. I went with a 4 node cluster (1 control node and 3 worker nodes) just because I wanted to tinker.
What follows in this blog is the complete build, from setting up the cluster, configuring the OS, to deploying Azure SQL Edge.
So let’s get to it!

Yay, delivery day!
Flashing the SD Cards
The first thing to do is flash the SD cards. I used Rufus but Etcher would work as well.
Grab the Ubuntu 20.04 ARM image from the website and flash all the cards: –
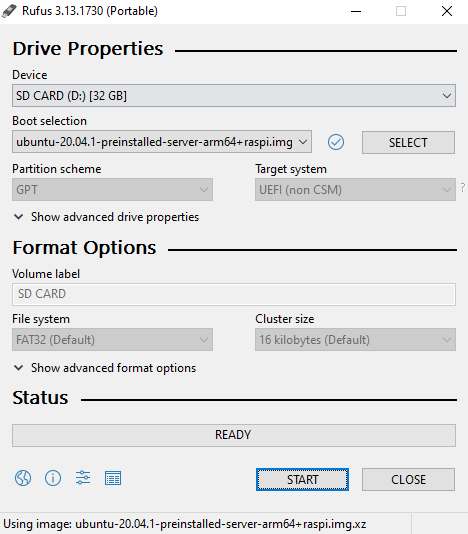
Once that’s done, it’s assembly time!
Building the cluster

So…many…little…screws…

But done! Now it’s time to plug it all in.
Plug all the SD cards into the Pis. Connect the USB hub to the mains and then plug the switch into your router. It’s plug and play so no need to mess around.
Once they’re connected, plug the Pis into the switch and then power them up (plug them into the USB Hub): –

(Ignore the zero in the background, it’s running pi-hole which I also recommend you check out!)
Setting a static IP address for each Raspberry Pi
We’re going to set a static IP address for each Pi on the network. Not doing anything fancy here with subnets, we’re just going to assign the Pis IP addresses that are currently not in use.
To find the Pis on the network with their current IP address we can run: –
nmap -sP 192.168.1.0/24
Tbh – nmap works but I usually use a Network Analyser app on my phone…it’s just easier (the output of nmap can be confusing).
Pick one Pi that’s going to be the control node and let’s ssh into it: –
ssh ubuntu@192.168.1.xx
When we first try to ssh we’ll have to change the ubuntu user password: –
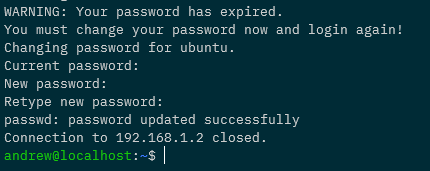
The default password is ubuntu. Change the password to anything you want, we’re going to be disabling the ubuntu user later anyway.
Once that’s done ssh back into the Pi.
Ok, now that we’re back on the Pi run: –
sudo nano /etc/netplan/50-cloud-init.yaml
And update the file to look similar to this: –
network:
ethernets:
eth0:
addresses: [192.168.1.53/24]
gateway4: 192.168.1.254
nameservers:
addresses: [192.168.1.5]
version: 2
192.168.1.53 is the address I’m setting for the Pi, but it can be pretty much anything on your network that’s not already in use. 192.168.1.254 is the gateway on my network, and 192.168.1.5 is my DNS server (the pi-hole), you can use 8.8.8.8 if you want to.
There’ll also be a load of text at the top of the file saying something along the lines of “changes here won’t persist“. Ignore it, I’ve found the changes do persist.
DISCLAIMER – There’s probably another (better?) way of setting a static IP address on Ubuntu 20.04, this is just what I’ve done and works for me.
Ok, once the file is updated we run: –
sudo netplan apply
This will freeze your existing ssh session. So close that and open another terminal…wait for the Pi to come back up on your network on the new IP address.
Creating a custom user on all nodes
Let’s not use the default ubuntu user anymore (just because). We’re going to create a new user, dbafromthecold (you can call your user anything you want 🙂 ): –
sudo adduser dbafromthecold
Run through the prompts and then add the new user to the sudo group: –
sudo usermod -aG sudo dbafromthecold
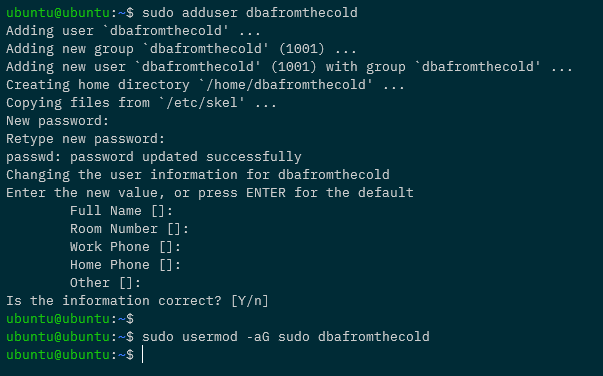
Cool, once that’s done, exit out of the Pi and ssh back in with the new user and run: –
sudo usermod --expiredate 1 ubuntu

This way no-one can ssh into the Pi using the default user: –

Setting up key based authentication for all nodes
Let’s now set up key based authentication (as I cannot be bothered typing out a password every time I want to ssh to a Pi).
I’m working in WSL2 here locally (I just prefer it) but a powershell session should work for everything we’re going to be running.
Anyway in WSL2 locally run: –
ssh-keygen

Follow the prompt to create the key. You can add a passphrase if you wish (I didn’t).
Ok, now let’s copy that to the pi: –
cat ./raspberrypi_k8s.pub | ssh dbafromthecold@192.168.1.53 "mkdir -p ~/.ssh && touch ~/.ssh/authorized_keys && chmod -R go= ~/.ssh && cat >> ~/.ssh/authorized_keys"
What this is going to do is copy the public key (raspberrypi_k8s.pub) up to the pi and store it as /home/dbafromthecold/.ssh/authorized_keys
This will allow us to specify the private key when connecting to the pi and use that to authenticate.
We’ll have to log in with the password one more time to get this working, so ssh with the password…and then immediately log out.
Now try to log in with the key: –
ssh -i raspberrypi_k8s dbafromthecold@192.168.1.53
If that doesn’t ask for a password and logs you in, it’s working!
As the Pi has a static IP address we can setup a ssh config file. So run: –
echo "Host k8s-control-1 HostName 192.168.1.53 User dbafromthecold IdentityFile ~/raspberrypi_k8s" > ~/.ssh/config
I’m going to call this Pi k8s-control-1, and once this file is created, I can ssh it to by: –
ssh k8s-control-1
Awesome stuff! We have setup key based authentication to our Pi!
Configuring the OS on all nodes
Next thing to do is rename the pi (to match the name we’ve given in our ssh config file): –
sudo hostnamectl set-hostname k8s-control-1 sudo reboot
That’ll rename the Pi to k8s-control-1 and then restart it. Wait for it to come back up and ssh in.

And we can see by the prompt and the hostname command…our Pi has been renamed!
Ok, now update the Pi: –
sudo apt-get update sudo apt-get upgrade
N.B. – This could take a while.
After that completes…we need to enable memory cgroups on the Pi. This is required for the Kubernetes installation to complete successfully so run:-
sudo nano /boot/firmware/cmdline.txt
and add
cgroup_enable=memory
to the end, so it looks like this: –

and then reboot again: –
sudo reboot
Installing Docker on all nodes
Getting there! Ok, let’s now install our container runtime…Docker.
sudo apt-get install -y docker.io
Then set docker to start on server startup: –
sudo systemctl enable docker
And then, so that we don’t have to use sudo each time we want to run a docker command: –
sudo usermod -aG docker dbafromthecold
Log out and then log back into the Pi for that to take effect. To confirm it’s working run: –
docker version

And now…let’s go ahead and install the components for kubernetes!
UPDATE – As of Kubernetes v1.20 Docker is deprecated as a container runtime. Containerd or CRI-O are the recommended container runtimes. I ran through the process of updating this cluster to containerd here
Installing Kubernetes components on all nodes
So we’re going to use kubeadm to install kubernetes but we also need kubectl (to admin the cluster) and the kubelet (which is an agent that runs on each Kubernetes node and isn’t installed via kubeadm).
So make sure the following are installed: –
sudo apt-get install -y apt-transport-https curl
Then add the Kubernetes GPG key: –
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
Add Kubernetes to the sources list: –
cat <<EOF | sudo tee /etc/apt/sources.list.d/kubernetes.list deb https://apt.kubernetes.io/ kubernetes-xenial main EOF
Ok, I know that the 20.04 code name isn’t xenial, it’s focal but if you use kubernetes-focal you’ll get this when running apt-get update: –
E: The repository ‘https://apt.kubernetes.io kubernetes-focal Release’ does not have a Release file.
So to avoid that error, we’re using xenial.
Anyway, now update sources on the box: –
sudo apt-get update
And we’re good to go and install the Kubernetes components: –
sudo apt-get install -y kubelet=1.19.2-00 kubeadm=1.19.2-00 kubectl=1.19.2-00
Going for version 1.19.2 for this install….absolutely no reason for it other than to show you that you can install specific versions!
Once the install has finished run the following: –
sudo apt-mark hold kubelet kubeadm kubectl
That’ll prevent the applications from being accidentally updated.
Building the Control Node
Right, we are good to go and create our control node! Kubeadm makes this simple! Simply run: –
sudo kubeadm init | tee kubeadm-init.out
What’s happening here is we’re creating our control node and saving the output to kubeadm-init.out.
This’ll take a few minutes to complete but once it does, we have a one node Kubernetes cluster!

Ok, so that we can use kubectl to admin the cluster: –
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
And now…we can run: –
kubectl get nodes

Don’t worry about the node being in a status of NotReady…it’ll come online after we deploy a pod network.
So let’s setup that pod network to allow the pods to communicate with each other. We’re going to use Weave for this: –
kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')"

A couple of minutes after that’s deployed, we’ll see the node becoming Ready: –

And we can check all the control plane components are running in the cluster: –
kubectl get pods -n kube-system

Now we have a one node Kubernetes cluster up and running!
Deploying a test application on the control node
Now that we have our one node cluster, let’s deploy a test nginx application to make sure all is working.
The first thing we need to do is remove the taint from the control node that prevents user applications (pods) from being deployed to it. So run: –
kubectl taint nodes $(hostname) node-role.kubernetes.io/master:NoSchedule-

And now we can deploy nginx: –
kubectl run nginx --image=nginx

Give that a few seconds and then confirm that the pod is up and running: –
kubectl get pods -o wide

Cool, the pod is up and running with an IP address of 10.32.0.4. We can run curl against it to confirm the application is working as expected: –
curl 10.32.0.4
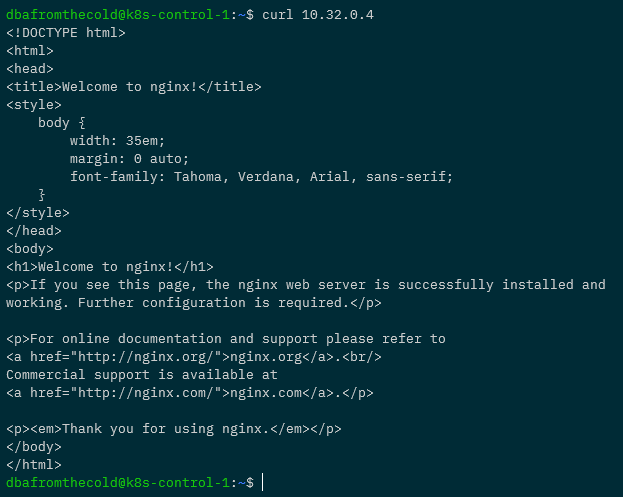
Boom! We have the correct response so we know we can deploy applications into our Kubernetes cluster! Leave the pod running as we’re going to need it in the next section.
Don’t do this now but if you want to add the taint back to the control node, run: –
kubectl taint nodes $(hostname) node-role.kubernetes.io/master:NoSchedule
Deploying MetalLb on the control node
There are no SQL client tools that’ll run on ARM infrastructure (at present) so we’ll need to connect to Azure SQL Edge from outside of the cluster. The way we’ll do that is with an external IP provided by a load balanced service.
In order for us to get those IP addresses we’ll need to deploy MetalLb to our cluster. MetalLb provides us with external IP addresses from a range we specify for any load balanced services we deploy.
To deploy MetalLb, run: –
kubectl apply -f https://raw.githubusercontent.com/google/metallb/v0.8.1/manifests/metallb.yaml
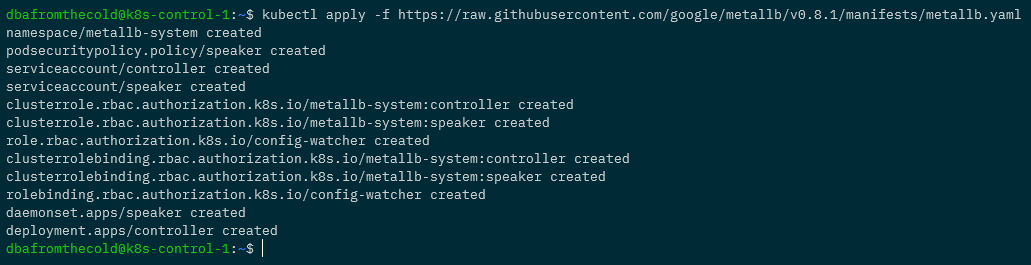
And now we need to create a config map specifying the range of IP addresses that MetalLb can use: –
apiVersion: v1 kind: ConfigMap metadata: namespace: metallb-system name: config data: config: | address-pools: - name: default protocol: layer2 addresses: - 192.168.1.100-192.168.1.110
What we’re doing here is specifying the IP range that MetalLb can assign to load balanced services as 192.168.1.100 to 192.168.1.110
You can use any range you want, just make sure that the IPs are not in use on your network.
Create the file as metallb-config.yaml and then deploy into the cluster: –
kubectl apply -f metallb-config.yaml

OK, to make sure everything is working…check the pods in the metallb-system namespace: –
kubectl get pods -n metallb-system

If they’re up and running we’re good to go and expose our nginx pod with a load balanced service:-
kubectl expose pod nginx --type=LoadBalancer --port=80 --target-port=80
Then confirm that the service created has an external IP: –
kubectl get services

Awesome! Ok, to really confirm everything is working…try to curl against that IP address from outside of the cluster (from our local machine): –
curl 192.168.1.100
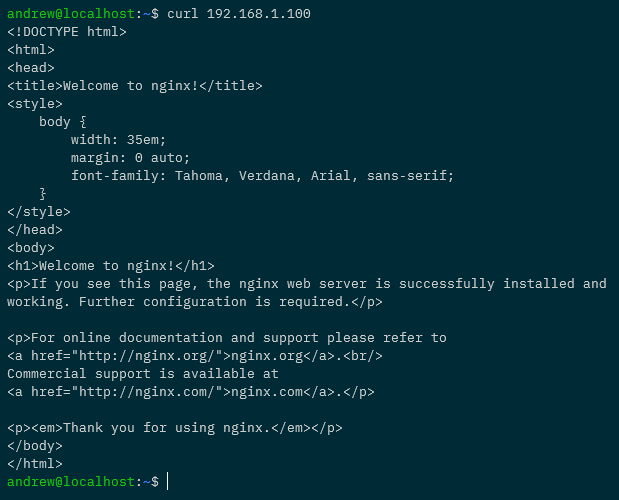
Woo hoo! All working, we can access applications running in our cluster externally!
Ok, quick tidy up…remove the pod and the service: –
kubectl delete pod nginx kubectl delete service nginx
And now we can add the taint back to the control node: –
kubectl taint nodes $(hostname) node-role.kubernetes.io/master:NoSchedule
Joining the other nodes to the cluster
Now that we have the control node up and running, and the worker nodes ready to go…let’s add them into the cluster!
First thing to do (on all the nodes) is add entries for each node in the /etc/hosts file. For example on my control node I have the following: –
192.168.1.54 k8s-node-1 192.168.1.55 k8s-node-2 192.168.1.56 k8s-node-3
Make sure each node has entries for all the other nodes in the cluster in the file…and then we’re ready to go!
Remember when we ran kubeadm init on the control node to create the cluster? At the end of the output there was something similar to: –
sudo kubeadm join k8s-control-1:6443 --token f5e0m6.u6hx5k9rekrt1ktk \ --discovery-token-ca-cert-hash sha256:fd3bed4669636d1f2bbba0fd58bcddffe6dd29bde82e0e80daf985a77d96c37b
Don’t worry if you didn’t save it, it’s in the kubeadm-init.out file we created. Or you can run this on the control node to regenerate the command: –
kubeadm token create --print-join-command
So let’s run that join command on each of the nodes: –
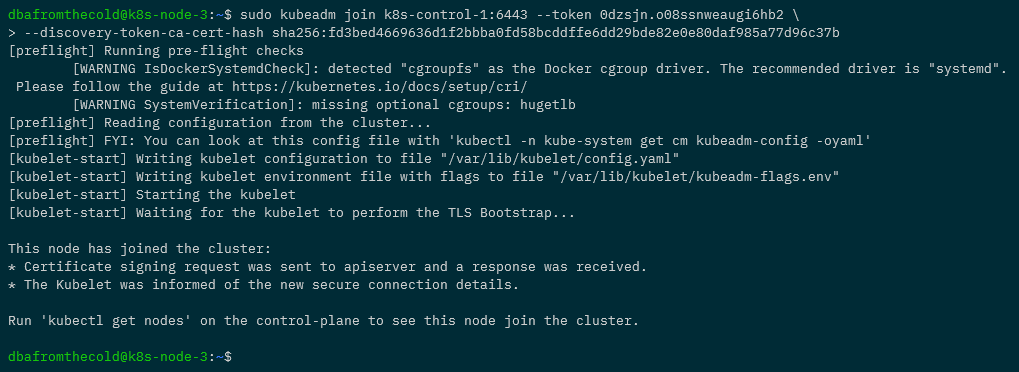
Once that’s done, we can confirm that all the nodes have joined and are ready to go by running: –
kubectl get nodes

Fantastic stuff, we have a Kubernetes cluster all built!
External kubectl access to cluster
Ok, we don’t want to be ssh’ing into the cluster each time we want to work with it, so let’s setup kubectl access from our local machine. What we’re going to do is grab the config file from the control node and pull it down locally.
Kubectl can be installed locally from here
Now on our local machine run: –
mkdir $HOME/.kube
And then pull down the config file: –
scp k8s-control-1:/home/dbafromthecold/.kube/config $HOME/.kube/
And to confirm that we can use kubectl locally to administer the cluster: –
kubectl get nodes
Wooo! Ok, phew…still with me? Right, it’s now time to (finally) deploy Azure SQL Edge to our cluster.
Running Azure SQL Edge
Alrighty, we’ve done a lot of config to get to this point but now we can deploy Azure SQL Edge. Here’s the yaml file to deploy: –
apiVersion: apps/v1
kind: Deployment
metadata:
name: sqledge-deployment
spec:
replicas: 1
selector:
matchLabels:
app: sqledge
template:
metadata:
labels:
app: sqledge
spec:
containers:
- name: azuresqledge
image: mcr.microsoft.com/azure-sql-edge:latest
ports:
- containerPort: 1433
env:
- name: MSSQL_PID
value: "Developer"
- name: ACCEPT_EULA
value: "Y"
- name: SA_PASSWORD
value: "Testing1122"
- name: MSSQL_AGENT_ENABLED
value: "TRUE"
- name: MSSQL_COLLATION
value: "SQL_Latin1_General_CP1_CI_AS"
- name: MSSQL_LCID
value: "1033"
terminationGracePeriodSeconds: 30
securityContext:
fsGroup: 10001
---
apiVersion: v1
kind: Service
metadata:
creationTimestamp: null
name: sqledge-deployment
spec:
ports:
- port: 1433
protocol: TCP
targetPort: 1433
selector:
app: sqledge
type: LoadBalancer
What this is going to do is create a deployment called sqledge-deployment with one pod running Azure SQL Edge and expose it with a load balanced service.
We can either create a deployment.yaml file or deploy it from a Gist like this: –
kubectl apply -f https://gist.githubusercontent.com/dbafromthecold/1a78438bc408406f341be4ac0774c2aa/raw/9f4984ead9032d6117a80ee16409485650258221/azure-sql-edge.yaml

Give it a few minutes for the Azure SQL Edge deployment to be pulled down from the MCR and then run: –
kubectl get all

If all has gone well, the pod will have a status of Running and we’ll have an external IP address for our service.
Which means we can connect to it and run a SQL command: –
mssql-cli -S 192.168.1.101 -U sa -P Testing1122 -Q "SELECT @@VERSION as [Version];"
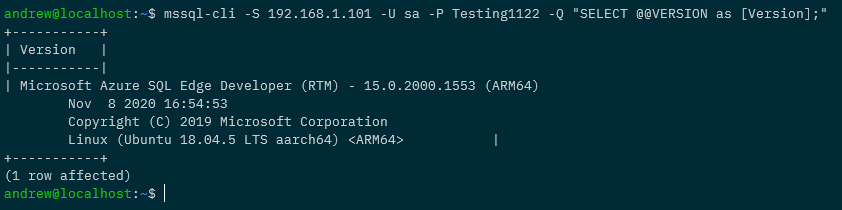
N.B. – I’m using the mssql-cli here but you can use SSMS or ADS.
And that’s it! We have Azure SQL Edge up and running in our Raspberry Pi Kubernetes cluster and we can connect to it externally!
Thanks for reading!

Great article! Thank you!
any idea why “kubectl get services” shows external IP as “pending”?
If the external IP stays as pending then there’s an issue assigning the external IP. Have a look at the logs of the metallb pods and describe the service that you’ve created. That should give you some insight on what went wrong.