A while ago I blogged about an awesome Chaos Engineering tools built by Eugenio Marzo (t) call KubeInvaders.
Since then Eugenio has updated the repo to make it easier to deploy KubeInvaders using Helm! So here’s how to deploy KubeInvaders to Azure Kubernetes Service using Helm.
Pre-requisities that need to be installed to run the code here are: –
Windows Subsystem for Linux (or a bash terminal)
Azure-Cli
Kubectl
Helm
First thing to do is log in with the azure cli: –
az login
Create a resource group: –
az group create --name kubeinvaders --location EASTUS
Spin up a AKS cluster: –
az aks create --resource-group kubeinvaders --name kubeinvadersclu --node-count 2
Get credentials to connect kubectl to AKS cluster: –
az aks get-credentials --resource-group kubeinvaders --name kubeinvadersclu
Confirm connection to AKS cluster: –
kubectl get nodes

Add the helm repo for the ingress-nginx controller: –
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
Confirm helm repositories: –
helm repo list

Install the ingress-nginx controller: –
helm install ingress-nginx ingress-nginx/ingress-nginx \ --create-namespace \ --namespace ingress-basic \ --set controller.service.annotations."service\.beta\.kubernetes\.io/azure-load-balancer-health-probe-request-path"=/healthz
EDIT – 2023-01 – Updated to add in the annotation
List resources in the ingress-basic namespace: –
kubectl get all -n ingress-basic

Note the external IP of the controller and set the IP address to a variable: –
IP="XX.XX.XXX.XX"
Set a DNS name for the external IP address to a variable: –
DNSNAME="SOMETHING-kubeinvaders"
Get the resource-id of the external ip: –
PUBLICIPID=$(az network public-ip list --query "[?ipAddress!=null]|[?contains(ipAddress, '$IP')].[id]" --output tsv)
Update external ip address with DNS name: –
az network public-ip update --ids $PUBLICIPID --dns-name $DNSNAME
Display the FQDN: –
az network public-ip show --ids $PUBLICIPID --query "[dnsSettings.fqdn]" --output tsv
![]()
Now we’re ready to deploy KubeInvaders!
Add the kubeinvaders helm repository: –
helm repo add kubeinvaders https://lucky-sideburn.github.io/helm-charts/
Confirm helm repositories: –
helm repo list

Create a kubeinvaders namespace: –
kubectl create namespace kubeinvaders
Deploy kubeinvaders: –
helm install kubeinvaders --set-string target_namespace="default" \ -n kubeinvaders kubeinvaders/kubeinvaders \ --set ingress.enabled=true \ --set ingress.hostName=SOMETHING-kubeinvaders.eastus.cloudapp.azure.com \ --set image.tag=v1.9
EDIT – 2023-01 – Updated to add in –set ingress.enabled=true
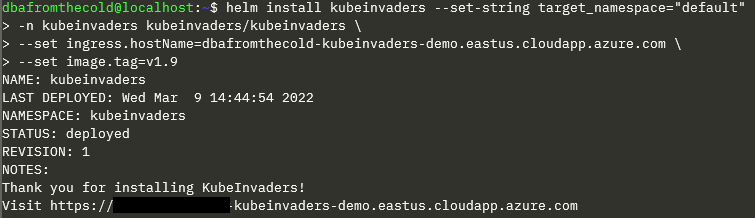
Now go to the FQDN set above in your browser.
If you get a 404 when going to the website it is because there’s a line missing from the annotations of the kubeinvaders ingress.
To fix this edit the ingress: –
kubectl edit ingress -n kubeinvaders
And add the following line: –
kubernetes.io/ingress.class: "nginx"

Save the updated ingress and go back to your FQDN and there is KubeInvaders!

Thanks for reading!