Docker Desktop is a great product imho. The ability to run Windows and Linux containers locally is great for development and has allowed me to really dig into SQL Server on Linux. I also love the fact that I no longer need to install SQL 2016/2017, I can run it in Windows containers.
However there are some differences between how Windows and Linux containers run in Docker Desktop. One of those differences being the default resource limits that are set.
Linux containers’ resource limits are set in the Advanced section of the Docker Desktop settings: –
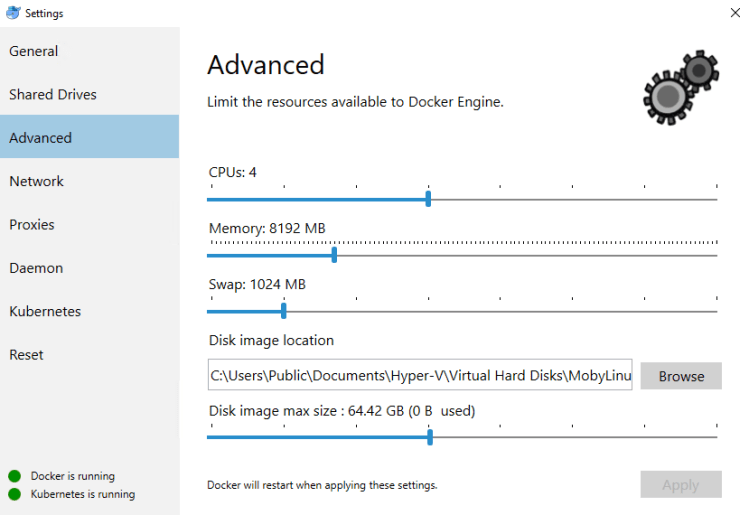
These setting control the resources available to the MobyLinuxVM, where the Linux containers run (and that’s how you get Linux containers running on Windows 10): –
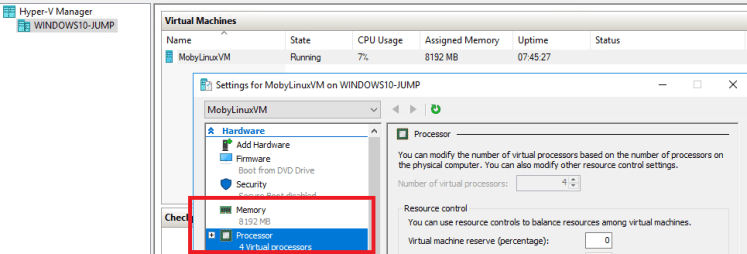
This can be confirmed by spinning up a Linux container (I’m running SQL but you can use any image): –
docker run -d -p 15789:1433 `
--env ACCEPT_EULA=Y --env SA_PASSWORD=Testing1122 `
--name testcontainer `
mcr.microsoft.com/mssql/server:2019-CTP3.0-ubuntu
And then running the following to confirm resources available to the container: –
docker exec testcontainer /bin/bash -c 'cat /proc/meminfo | grep MemTotal'
docker exec testcontainer nproc

The container has the memory and CPUs that were set in the Docker settings.
But what about Windows containers? When you switch to Windows containers in Docker, there’s no option to set CPU and memory limits. This is because Windows containers run on the host, not in the MobyLinuxVM. The host I’m running on has 4 cores and 32GB of RAM, so the containers should have all the host resources available to it, right?
This can be checked by spinning up a Windows container:-
docker run -d -p 15789:1433 `
--env ACCEPT_EULA=Y --env SA_PASSWORD=Testing1122 `
--name testcontainer `
microsoft/mssql-server-windows-developer:latest
And then running: –
docker exec testcontainer systeminfo | select-string 'Total Physical Memory'
docker exec testcontainer systeminfo | select-string 'Processor'

Ok, the container can only see the one processor (same as my host), so let’s exec into the container and check the number of cores.
docker exec -i testcontainer powershell
Get-WmiObject -class Win32_processor | Format-Table Name,NumberOfCores,NumberOfLogicalProcessors

Ok, so it looks like Windows containers are limited to 2 cores and 1GB of RAM by default. Not exactly great if we’re running SQL Server, but can we change those limits? As I said earlier, there’s no way to adjust the resources available to Windows containers in the Docker settings.
What we can do is change the resources available to the individual containers at runtime using the –cpus and –memory options:-
docker run -d -p 15799:1433 `
--cpus=3 --memory=8192m `
--env ACCEPT_EULA=Y --env SA_PASSWORD=Testing1122 `
--name testcontainer2 `
microsoft/mssql-server-windows-developer:latest
N.B. – I’m setting 3 cores as when I tried 4, the container crashed (something to watch out for).
Now if we check the resources again: –
docker exec testcontainer2 systeminfo | select-string 'Total Physical Memory'
docker exec testcontainer2 systeminfo | select-string 'Processor'

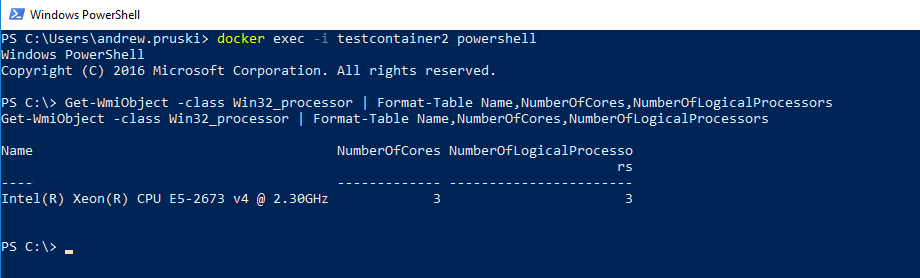
The memory available to the container has increased, let’s exec into the container and check the number of cores: –
docker exec -i testcontainer2 powershell
Get-WmiObject -class Win32_processor | Format-Table Name,NumberOfCores,NumberOfLogicalProcessors
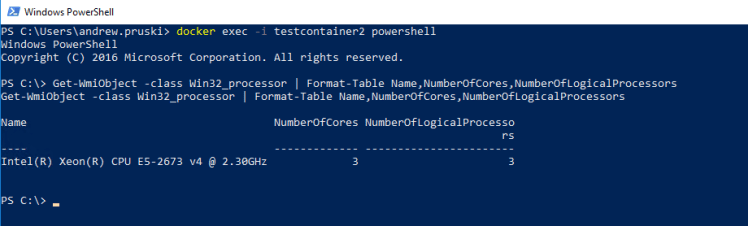
The core count has also increased.
So the limits of Windows containers running on Docker Desktop can be altered, just not in the settings as with Linux containers.
Thanks for reading!