I’ve previously blogged about running SQL Server in ACS but Microsoft has now released a new version still called Azure Container Services (AKS instead of ACS however) but now specifically tailored to building Kubernetes clusters.
EDIT – Azure Container Services (AKS) has been renamed to Azure Kubernetes Services. Blog title has been updated
There are some differences to the original ACS (making the process simpler) so let’s run through setting up a Kubernetes cluster running SQL Server in AKS.
Ok, first thing to do is install the CLI (I’m going to work from a Bash shell on my desktop): –
echo "deb [arch=amd64] https://packages.microsoft.com/repos/azure-cli/ wheezy main" | \
sudo tee /etc/apt/sources.list.d/azure-cli.list
sudo apt-key adv --keyserver packages.microsoft.com --recv-keys 52E16F86FEE04B979B07E28DB02C46DF417A0893
sudo apt-get install apt-transport-https
sudo apt-get update && sudo apt-get install azure-cli
Check the version of the CLI installed (make sure it’s at least version 2.0.20): –
az --version
Then login to Azure in the shell (and follow the instructions): –
az login
As AKS is still in preview a flag needs to be enabled on your Azure subscription.
To do this run: –
az provider register -n Microsoft.ContainerService
You can check that the flag has been successfully enabled by running: –
az provider show -n Microsoft.ContainerService
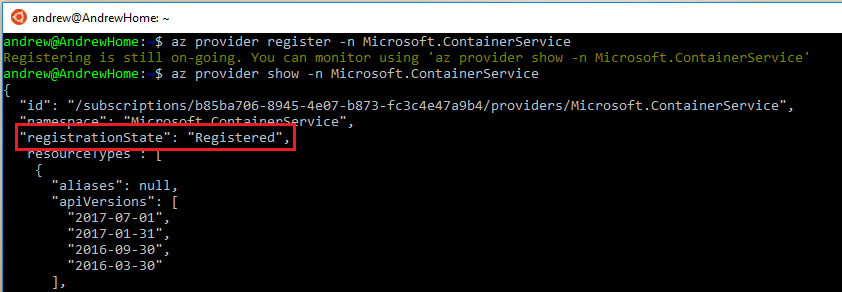
Cool. Now we’re good to go with setting up a Kubernetes cluster! Same as the original ACS, a resource group needs to be created to hold all the objects in the cloud: –
az group create --name ApResourceGroup1 --location ukwest
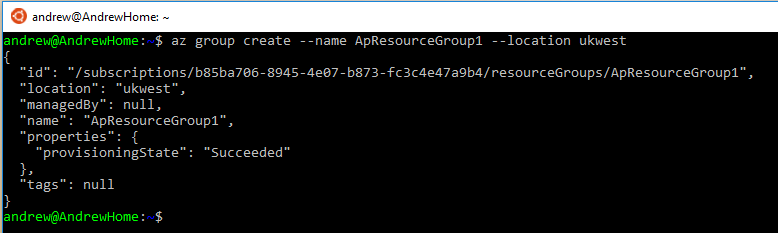
And now the cluster can be created. I’m going to create a two node cluster by running: –
az aks create --resource-group ApResourceGroup1 --name mySQLK8sCluster1 --node-count 2 --generate-ssh-keys
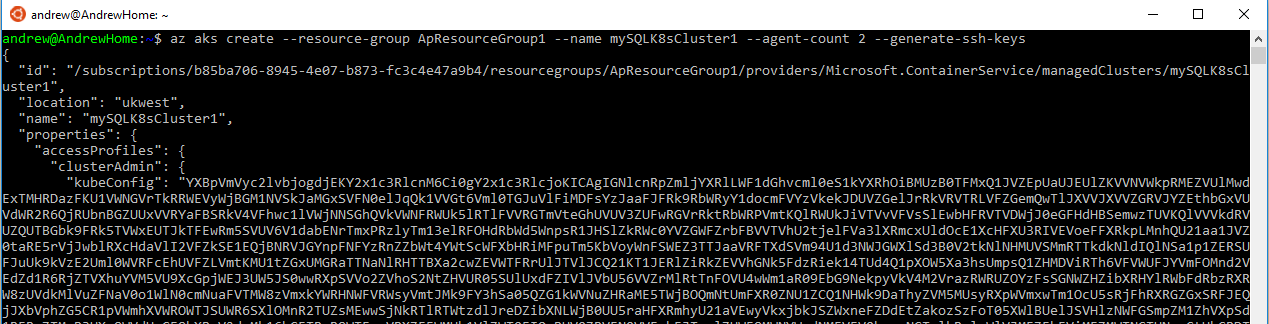
EDIT: updated agent-code to node-count has this switch seems to have changed since I wrote this post
What’s cool about this is the amount of objects it’s creating in the background: –
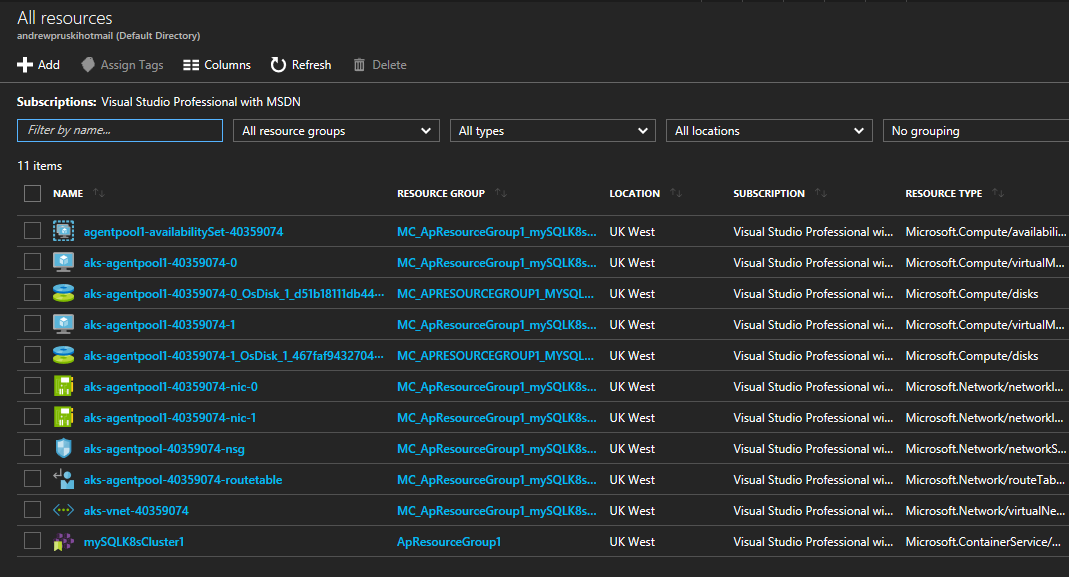
All that from one line of code!
Once that’s complete, Kubectl needs to be installed locally to manage the cluster: –
az aks install-cli
And then I need to connect my local shell to the cluster: –
az aks get-credentials --resource-group ApResourceGroup1 --name mySQLK8sCluster1
Ok, let’s check the nodes in the cluster: –
kubectl get nodes
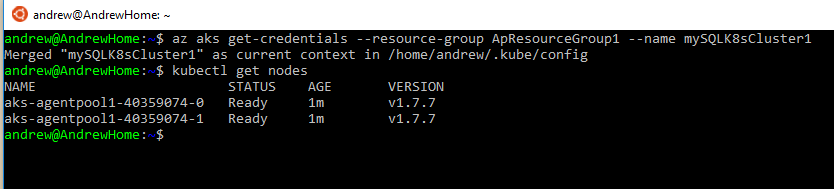
Awesome, I have two nodes up and running in my cluster!
Next thing to do is spin up SQL Server in a container within the cluster. To do this I’m going to build it from a yaml file: –
nano sqlserver.yml
And drop the following into it: –
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: sqlserver
labels:
app: sqlserver
spec:
replicas: 1
template:
metadata:
labels:
name: sqlserver
spec:
containers:
- name: sqlserver1
image: microsoft/mssql-server-linux:latest
ports:
- containerPort: 1433
env:
- name: SA_PASSWORD
value: "Testing1122"
- name: ACCEPT_EULA
value: "Y"
---
apiVersion: v1
kind: Service
metadata:
name: sqlserver-service
spec:
ports:
- name: sqlserver
port: 1433
targetPort: 1433
selector:
name: sqlserver
type: LoadBalancer
This will spin up a container within the cluster (as a deployment) and create a load balanced service with an external IP so that I can connect to SQL Server from my desktop. So now run: –
kubectl create -f sqlserver.yml
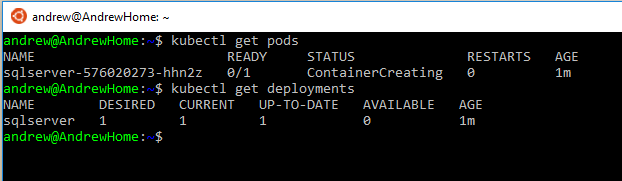
Once that’s complete we can run some commands to view the objects created. To check the SQL Server container created: –
kubectl get pods
To check on the deployment:-
kubectl get deployments
And finally, to check on the service: –
kubectl get service
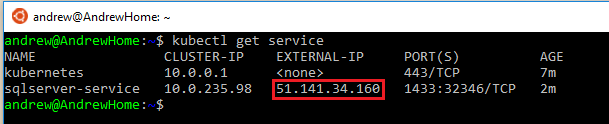
Once the service has an external IP, I can use that to connect to SQL Server within my Kubernetes cluster in AKS!

How awesome is that! Microsoft have made this a nice and simple way of getting into running Kubernetes in Azure. I’m going to play around with this some more 🙂
Last thing, to remove all the objects built in this demo you just need to run: –
az group delete --name ApResourceGroup1
Thanks for reading!

This is really fascinating. I stumbled upon this blog while I was searching for ways to deploy and replicate sql server containers across kubernetes nodes. One thing I’m curious about is would this be useful to solve execution times with long running queries of large databases? Can my application point to the sql server, as a data store, which is deployed in Kubernetes? If this solution can help with running distributed queries, it would be amazing.
Thank you for the great post
SQL Server can be deployed as a Kubernetes cluster, I’d check out James Anderson’s post here: – http://thedatabaseavenger.com/2017/06/orchastrating-sql-server-with-kubernetes/
Thanks for the reply. In fact, I checked out the link you provided before I run into your blog. My question, to elaborate, was if we deploy sql server as kubernetes cluster, would we be able to run queries that will be executed on each worker node? Can we say that it would be count as distributed database? For example if I run a select query on a supposedly large database, would that execution be shared among the worker nodes hence query being distributed would result in faster response?
My understanding is that there’s no auto-distribution of queries. The SQL instances in containers managed by Kubernetes behave as normal SQL instances. Kubernetes just manages the containers (nodes) that SQL is running in.
So can we say that sql server containers are not scalable in Kubernetes? Because one of the awesome advantages of Kubernetes is its scalability but in the sql server container context then this won’t hold true since it would just be replicas of instances. Is that right?
Yes, the advantage of running SQL Server in containers is the ease of deployment. Kubernetes provides high availability but not scalability for SQL instances.
Note – Happy to be corrected if wrong here
Love your article. I have one question about maintenance and upgrades.
If I would like to deploy new version of SQL container , how can I stop or remove only SQL server service?
Delete whole resource group is not an option in this scenario
Thanks.
Hi Vlad,
Individual components of the setup can be deleted. However if you delete the pod that sql is running in a new one will automatically be spun up.
I think you’re after: kubectl delete deployment sqlserver
That will drop the pods that sql is running in but keep your resource group and nodes (so that you can redeploy). Just be careful as it won’t drop the service, you’ll have to drop that separately.
I’d like to work out how to redeploy a pod to an existing service and will post that in a future blog.
Yep, that works:
kubectl delete deployment sqlserver
kubectl get service
kubectl delete service sqlserver-service
If you don’t mind , I have one more question…
Do you know how I can change default IP port for SQL let say to 4433 from 1433? I tried to modify your yaml , but it didn’t work fro me.
No problem at all!
There’s a couple of ways you can do it. First one is to change the port that SQL is listening on, open that port in the container, and map the service to that port. The .yml file to set that up is here: https://tinyurl.com/y8yty43l
Second way is to leave SQL running on its default port, open another port in the service, and map that port back to SQL defaul port in the container. The .yml file to do that is here: https://tinyurl.com/y9b3guhd
Hope that helps!
Thank you. I am relatively new to K8S and wanted to check how SQL Server can be containerized. This clearly shows how to do it on the Azure platform. Good points made on scale vs HA for SQL Server with AKS.
So, basically basic SQL Server and not SQL PDW in AKS, right?
Also, it is a SQL Server Pod, (running on a linux host ), abstracting the container running SQL Server i.e Not supported on windows hosts yet – correct?
Yes, it’s SQL Server and you can provision Windows hosts in a K8s AKS cluster. Just make sure you use the windows sql server image.