In a previous post I talked about an issue with storage failover when a Kubernetes node goes offline.
In a nutshell, the issue is that the attachdetach-controller in Kubernetes won’t detach storage from an offline node until that node is either brought back online or is removed from the cluster. What this means is that a pod spinning up on a new node that requires that storage can’t come online.
UPDATE – This issue has been resolved in Kubernetes version 1.26. Details are on this github issue: –
https://github.com/kubernetes/kubernetes/issues/65392
And there’s more on the official Kubernetes blog (when a feature called non-graceful node shutdown when into beta): –
https://kubernetes.io/blog/2022/12/16/kubernetes-1-26-non-graceful-node-shutdown-beta/
Aka, if you’re running SQL Server in Kubernetes and a node fails, SQL won’t be able to come back online until someone manually brings the node online or deletes the node.
Not great tbh, and it’s been a blocker for my PoC testing.
However, there are ways around this…one of them is by a product called Portworx which I’m going to demo here.
DISCLAIMER – I now work for Pure Storage who own Portworx…there are other options to get around this issue (Azure Arc Data Services being one) but I’ve found Portworx to be the simplest solution and everything I’m demoing here is completely free so you can go and test it for yourself
So let’s run through using Portworx to first create storage in Kubernetes for SQL Server, and then test a node failure.
First thing to do is log into Azure using the azure-cli: –
az login
Then create a role for portworx in Azure: –
az role definition create --role-definition '{
"Name": "portworx",
"Description": "",
"AssignableScopes": [
"/subscriptions/<subscription-id>"
],
"Actions": [
"Microsoft.ContainerService/managedClusters/agentPools/read",
"Microsoft.Compute/disks/delete",
"Microsoft.Compute/disks/write",
"Microsoft.Compute/disks/read",
"Microsoft.Compute/virtualMachines/write",
"Microsoft.Compute/virtualMachines/read",
"Microsoft.Compute/virtualMachineScaleSets/virtualMachines/write",
"Microsoft.Compute/virtualMachineScaleSets/virtualMachines/read"
],
"NotActions": [],
"DataActions": [],
"NotDataActions": []
}'
Then grab the resource group that the Kubernetes cluster resources are in: –
az aks show --name <cluster-name> --resource-group <cluster-resource-group> | jq -r '.nodeResourceGroup'
Then create a service principal in Azure dropping the subscription ID and Kubernetes resource group in: –
az ad sp create-for-rbac --role="portworx" --scopes="/subscriptions/<subscription-id>/resourceGroups/<resource-group>"
Now create secret for portworx to access Azure APIs using the service principal’s details: –
kubectl create secret generic -n kube-system px-azure --from-literal=AZURE_TENANT_ID=<tenant> \
--from-literal=AZURE_CLIENT_ID=<appId> \
--from-literal=AZURE_CLIENT_SECRET=<password>
Now we need to go to the Portworx Portal to generate a yaml file to deploy to the AKS cluster: –
https://central.portworx.com
Create an account and once in, select Portworx Enterprise (don’t worry there’s a free option coming): –

Now select Portworx Essentials and click Continue: –

On the next page, leave everything as the default and click Next: –

Then on the Storage page, select the Cloud option, then Azure, and pick a size for the disks (I went with 50GB): –

Leave everything as the default settings on the next page (the Network page) and click Next.
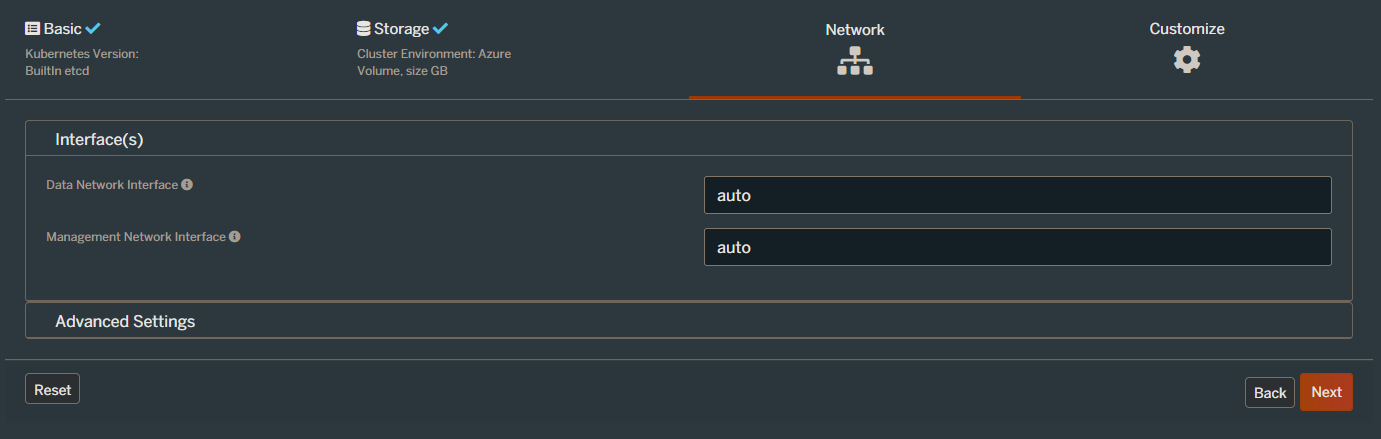
And on the final, Customise page, select AKS and hit Finish: –

N.B. – you can also go into the Advanced Settings section and choose what options to deploy for Portworx here. I disabled pretty much everything for this demo but you can leave the defaults.
Ok, on the next page we have some instructions. The first thing to do is deploy the Portworx operator: –
kubectl apply -f 'https://install.portworx.com/2.10?comp=pxoperator'
Once that’s deployed we can download the spec generated: –

Great! We are ready to deploy Portworx to the cluster: –
kubectl apply -f portworx_essentials_sql_demo.yaml
Let’s have a look at some of the resource that deployed. View the Portworx pods: –
kubectl get pods -n=kube-system -l name=portworx -o wide
N.B. – These may take around 5 minutes to come online

To confirm Portworx’s status: –
PX_POD=$(kubectl get pods -l name=portworx -n kube-system -o jsonpath='{.items[0].metadata.name}')
kubectl exec $PX_POD -n kube-system -- /opt/pwx/bin/pxctl status

Now we can create a Portworx storage class. Create the following px_storageclass.yaml file: –
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: px-mssql-sc
provisioner: kubernetes.io/portworx-volume
parameters:
repl: "3"
io_profile: "db_remote"
priority_io: "high"
allowVolumeExpansion: true
Then deploy to the cluster: –
kubectl apply -f .\px_storageclass.yaml
Confirm the storage class is now available: –
kubectl get storageclass

Now create a px_pvc.yaml file referencing the Portworx storage class: –
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mssql-system
annotations:
volume.beta.kubernetes.io/storage-class: px-mssql-sc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mssql-data
annotations:
volume.beta.kubernetes.io/storage-class: px-mssql-sc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mssql-log
annotations:
volume.beta.kubernetes.io/storage-class: px-mssql-sc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
Create the PVCs: –
kubectl apply -f .\px_pvc.yaml.yaml
Confirm the PVCs: –
kubectl get pvc
And the corresponding PVs: –
kubectl get pv

Now we can deploy SQL Server using the PVCs. Create the following px_sqlserver.yaml file: –
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: sqlserver
name: sqlserver
spec:
replicas: 1
selector:
matchLabels:
app: sqlserver
template:
metadata:
creationTimestamp: null
labels:
app: sqlserver
spec:
securityContext:
fsGroup: 10001
containers:
- image: mcr.microsoft.com/mssql/server:2019-CU11-ubuntu-18.04
name: sqlserver
env:
- name: ACCEPT_EULA
value: "Y"
- name: MSSQL_SA_PASSWORD
value: "Testing1122"
resources:
requests:
memory: "1024Mi"
cpu: "1000m"
limits:
memory: "2048Mi"
cpu: "2000m"
volumeMounts:
- name: system
mountPath: /var/opt/mssql
- name: user
mountPath: /var/opt/sqlserver/data
- name: log
mountPath: /var/opt/sqlserver/log
tolerations:
- key: "node.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 10
- key: "node.kubernetes.io/not-ready"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 10
volumes:
- name: system
persistentVolumeClaim:
claimName: mssql-system
- name: user
persistentVolumeClaim:
claimName: mssql-data
- name: log
persistentVolumeClaim:
claimName: mssql-log
strategy:
type: Recreate
And deploy: –
kubectl apply -f .\px_sqlserver.yaml
Confirm the deployment: –
kubectl get deployments
View pod created: –
kubectl get pods

View pod events: –
kubectl describe pods
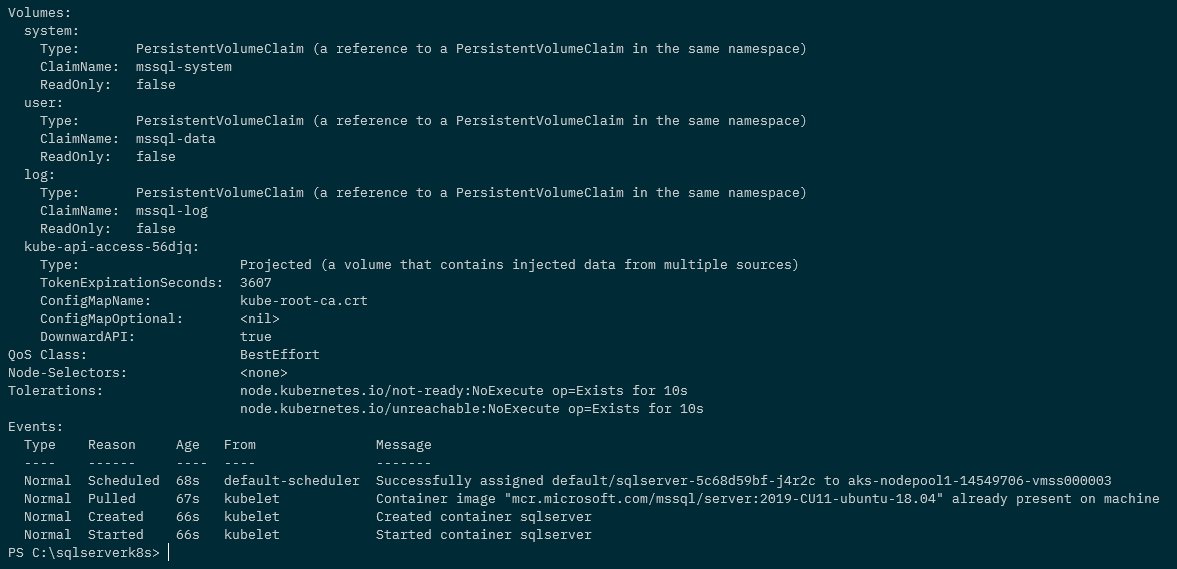
N.B. – Note that we have the PVCs attached to the pod but there are no events for the attachdetach-controller in the pod events
Ok, now that we have a pod running SQL Server in the cluster…let’s see what happens when we shut down the node the pod is running on.
Confirm the node that the pod is running on: –
kubectl get pods -o wide

And then shut that node down in the portal: –
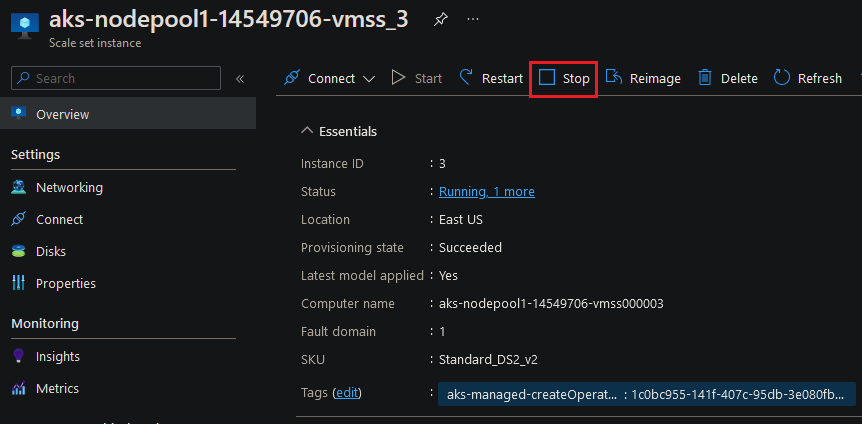
Confirm the node is down: –
kubectl get nodes
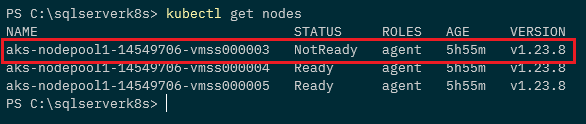
And then watch the pods: –
kubectl get pods --watch

A new pod is spun up and goes into the running status on another node: –
kubectl get pods -o wide

Ok, the old pod will stay in the terminated status until the offline node is either brought back online or removed from the cluster…but we have SQL Server up and running!
So Portworx fixes the issue that we saw in my previous post…which was a show stopper when I was running a proof of concept for SQL Server in Azure Kubernetes Service.
Thanks for reading!
