Partitioning tables is a great tool to increase the manageability of your data. Being able to move large amounts of data in and out of a table quickly is incredibly helpful.
However, partitioning comes with a whole bunch of caveats and we need to be aware of what’s going on. This especially applies when creating indexes on partitioned tables, as there are a couple of things we need to be aware of.
So let’s run through a demo so that I can show you how SQL behaves when creating indexes on partitioned tables. First, create a database: –
CREATE DATABASE PartitioningDemo; GO
And now let’s build a Partition Function & Scheme to partition a table by year: –
USE [PartitioningDemo];
GO
CREATE PARTITION FUNCTION PF_PartitionedTable(DATE)
AS RANGE RIGHT
FOR VALUES ('2017-06-01','2018-01-01','2019-01-01');
GO
CREATE PARTITION SCHEME PS_PartitionedTable
AS PARTITION PF_PartitionedTable
ALL TO ([PRIMARY]);
GO
N.B. – Keeping it simple, all partitions going to the PRIMARY filegroup. You wouldn’t do this when creating a normal partitioned table but I want to show you the index structure, so for the purposes of this demo, the location of the partitions doesn’t matter.
And now we can create the table. Really simple table, with a DATE column as my partitioning key (the column that defines the partitions): –
CREATE TABLE dbo.PartitionedTable (ID INT IDENTITY(1,1), ColA VARCHAR(10), ColB VARCHAR(10), CreatedDate DATE) ON PS_PartitionedTable(CreatedDate); GO
Now let’s insert some data into the table: –
SET NOCOUNT ON;
SET STATISTICS IO OFF;
DECLARE @FromDate date = '2017-01-01';
DECLARE @ToDate date = '2018-01-01';
INSERT INTO dbo.PartitionedTable
SELECT
REPLICATE('A',10),
REPLICATE('B',10),
DATEADD(DD,FLOOR(RAND()*(DATEDIFF(DD,@FromDate,@ToDate))),@FromDate);
GO 1000
Great, now we can look at creating indexes on the table.
First let’s look at creating clustered indexes on this table. Now, when creating a UNIQUE CLUSTERED INDEX on a partitioned table, the partitioning key must be explicitly defined in the index definition.
Try creating this index: –
CREATE UNIQUE CLUSTERED INDEX [IX_ID_PartitionedTable] ON dbo.PartitionedTable (ID) ON PS_PartitionedTable(CreatedDate); GO
Whoops!
Msg 1908, Level 16, State 1, Line 26
Column ‘CreatedDate’ is partitioning column of the index ‘IX_ID_PartitionedTable’.
Partition columns for a unique index must be a subset of the index key.
This is generated as we did not specify the CreatedDate column in our index. SQL needs the partitioning key to be explicitly defined in all unique indexes on partitioned tables. This is so that SQL can determine the uniqueness of that index by checking one partition.
So, let’s change the index to be non-unique: –
CREATE CLUSTERED INDEX [IX_ID_PartitionedTable] ON dbo.PartitionedTable (ID) ON PS_PartitionedTable(CreatedDate); GO
As it’s non-unique, SQL will create that no problem. But let’s look at what’s happened in the background. I’m going to use DBCC IND & DBCC PAGE to delve into the index. First let’s see what files are assigned to the database: –
EXEC sp_helpfile; GO

Simple database, so the fileID will be 1 (the .MDF file)
Now look at the pages assigned to the clustered index: –
DBCC IND('PartitioningDemo','PartitionedTable',1);
GO
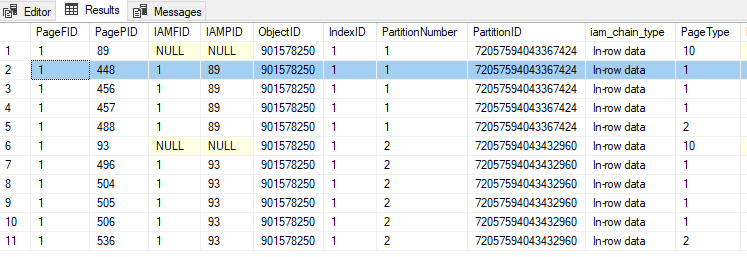
PageID 448 is a data page (type 1) so we’ll drop that into DBCC PAGE along with the FileID and have a look: –
DBCC TRACEON(3604);
GO
DBCC PAGE ('PartitioningDemo',1,448,3);
GO

Looking at that data page, we can see that SQL has added a UNIQUIFIER column. Now this is standard SQL behaviour, SQL does this to all non-unique clustered indexes whether they are on a partitioned table or not.
But also look at the CreatedDate column. It’s after the ID column on the page. If this was a non-partitioned table, we would see that after ColA & ColB (the order the columns are on the table). This has happened because SQL has implicitly added the partitioning key into the index definition, which has changed the physical order of the data on the page.
OK, so what about nonclustered indexes? Well it’s the same story when it comes to unique nonclustered indexes. The partitioning key must be explicitly defined in the index. But what about non-unique nonclustered indexes? Let’s have a look.
Let’s drop the clustered index created previously and create a non-unique nonclustered index: –
DROP INDEX IF EXISTS [IX_ID_PartitionedTable] ON dbo.PartitionedTable; CREATE NONCLUSTERED INDEX [IX_ColA_PartitionedTable] ON dbo.PartitionedTable (ColA) ON PS_PartitionedTable(CreatedDate); GO
N.B. – this is an aligned nonlclustered index. Meaning that is using the same partition scheme and key as the base table, you can read more about aligned and nonaligned nonclustered indexes here.
Let’s do the same to look at the index data: –
DBCC IND('PartitioningDemo','PartitionedTable',2);
GO
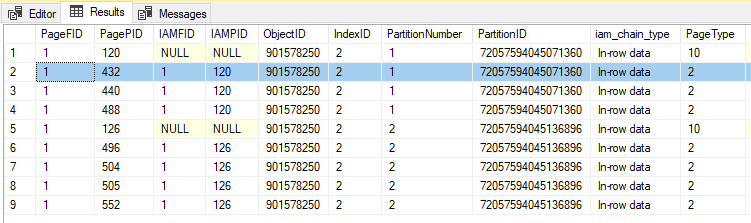
PageID 432 is an index page (type 2) so we’ll drop that into DBCC PAGE along with the FileID and have a look: –
DBCC TRACEON(3604);
GO
DBCC PAGE ('PartitioningDemo',1,432,3);
GO
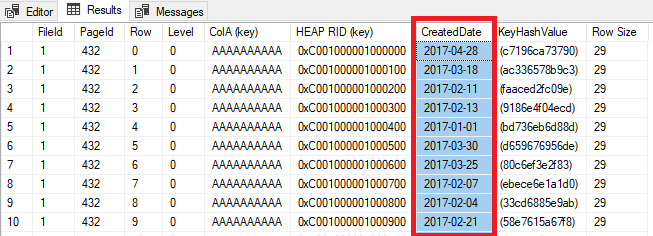
This time I have got my results back in a grid. But look! CreatedDate is there!
SQL has implicitly added the partitioning key to my index as an included column.
OK, but why does this matter? Well, this can catch you out in certain situations. Let’s run a quick test on trying to SWITCH a partition from the table we’ve built.
First let’s create the switch table: –
CREATE TABLE dbo.PartitionedTable_Switch (ID INT IDENTITY(1,1), ColA VARCHAR(10), ColB VARCHAR(10), CreatedDate DATE) ON [PRIMARY]; CREATE NONCLUSTERED INDEX [IX_ColA_PartitionedTable_Switch] ON dbo.PartitionedTable_Switch (ColA) ON [PRIMARY]; GO
Now, this table is not partitioned. Standard really, non-partitioned table as an archive for old data in the table.
Let’s see what happens when we run a SWITCH operation: –
ALTER TABLE [dbo].PartitionedTable SWITCH PARTITION 1 TO [dbo].PartitionedTable_Switch; GO
Oh no!
Msg 4947, Level 16, State 1, Line 122
ALTER TABLE SWITCH statement failed. There is no identical index in source table ‘PartitioningDemo.dbo.PartitionedTable’
for the index ‘IX_ColA_PartitionedTable_Switch’ in target table ‘PartitioningDemo.dbo.PartitionedTable_Switch’ .
This has happened because even though the t-sql statements for both indexes are the same, the partitioned table’s index has the partitioning key as an included column and the switch table does not.
We can check this by altering the index on the switch table: –
CREATE NONCLUSTERED INDEX [IX_ColA_PartitionedTable_Switch] ON dbo.PartitionedTable_Switch
(ColA)
INCLUDE (CreatedDate)
WITH (DROP_EXISTING=ON)
ON [PRIMARY];
GO
And now the switch will work!
ALTER TABLE [dbo].PartitionedTable SWITCH PARTITION 1 TO [dbo].PartitionedTable_Switch; GO
The best way to prevent this from happening is to create a unique clustered index on your partitioning key (with something like an identity integer column if the key isn’t unique by itself). That way the partitioning key will automatically be in all of your nonclustered indexes.
Thanks for reading!
