When working with partitioning the SWITCH operation has to be my favourite. The ability to move a large amount of data from one table to another as a META DATA ONLY operation is absolutely fantastic.
What’s also cool is that we can switch data into a non-partitioned table. Makes life a bit easier not having to manage two sets of partitions!
However, there is a bit of a gotcha when doing this. Let’s run through a quick demo.
First create a database with a partitioned table: –
CREATE DATABASE [PartitioningDemo]
GO
USE [PartitioningDemo];
GO
CREATE PARTITION FUNCTION PF_PartitionedTable(DATE)
AS RANGE RIGHT
FOR VALUES ('2011-01-01','2012-01-01','2013-01-01',
'2014-01-01','2015-01-01','2016-01-01',
'2017-01-01');
GO
CREATE PARTITION SCHEME PS_PartitionedTable
AS PARTITION PF_PartitionedTable
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.PartitionedTable
(ID INT IDENTITY(1,1),
ColA VARCHAR(10),
ColB VARCHAR(10),
CreatedDate DATE)
ON PS_PartitionedTable(CreatedDate);
GO
For a more in-depth look at what I’m doing, my series on partitioning can be found here
So let’s insert some test data:-
SET NOCOUNT ON;
DECLARE @FromDate date = '2011-01-01';
DECLARE @ToDate date = '2017-01-01';
INSERT INTO dbo.PartitionedTable
SELECT
REPLICATE('A',10),
REPLICATE('B',10),
DATEADD(DD,FLOOR(RAND()*(DATEDIFF(DD,@FromDate,@ToDate))),@FromDate);
GO 1000
We can check the data and partitions by running: –
SELECT
p.partition_number, p.partition_id, fg.name AS [filegroup],
r.boundary_id, CONVERT(DATE,r.value) AS BoundaryValue, p.rows
FROM
sys.tables AS t
INNER JOIN
sys.indexes AS i ON t.object_id = i.object_id
INNER JOIN
sys.partitions AS p ON i.object_id = p.object_id AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON a.container_id = p.hobt_id
INNER JOIN
sys.filegroups fg ON fg.data_space_id = a.data_space_id
INNER JOIN
sys.partition_schemes AS s ON i.data_space_id = s.data_space_id
INNER JOIN
sys.partition_functions AS f ON s.function_id = f.function_id
LEFT OUTER JOIN
sys.partition_range_values AS r ON f.function_id = r.function_id
AND r.boundary_id = p.partition_number
WHERE
i.type <= 1 AND a.type = 1
AND
t.name = 'PartitionedTable'
ORDER BY
p.partition_number
DESC;

Now let’s create the “switch” table: –
USE [PartitioningDemo]; GO CREATE TABLE dbo.PartitionedTable_Switch (ID INT IDENTITY(1,1), ColA VARCHAR(10), ColB VARCHAR(10), CreatedDate DATE) ON [PRIMARY]; GO
N.B. – Keeping it simple, a non-partitioned table on the PRIMARY filegroup (the same filegroup as all my partitions in the “source” table).
OK, let’s switch one of the partitions to the switch table: –
ALTER TABLE [dbo].PartitionedTable SWITCH PARTITION 3 TO [dbo].PartitionedTable_Switch; GO

All good! Worked exactly as expected 🙂
But what happens when say, because of some issue, we need to switch that data back?
ALTER TABLE [dbo].PartitionedTable_Switch
SWITCH
TO [dbo].PartitionedTable
PARTITION 3;
GO
Oh no!
Msg 4982, Level 16, State 1, Line 4
ALTER TABLE SWITCH statement failed. Check constraints of source table ‘PartitioningDemo.dbo.PartitionedTable_Switch’
allow values that are not allowed by range defined by partition 3 on target table ‘PartitioningDemo.dbo.PartitionedTable’.
What’s happened??
Well, we’re trying to insert data into a partition that has constraints on it. The partition has a lower boundary of 2012-01-01 and an upper boundary of 2013-01-01. Meaning that no data can go into that partition that has values in the CreatedDate field that isn’t greater than or equal to 2012-01-01 and less than 2013-01-01.
But our switch table doesn’t have these constraints. SQL thinks that there could be data in the switch table that doesn’t fit into the destination partition.
So we need to tell SQL that the data in the switch table will fit into the partition. And we do that by dropping a constraint onto the table: –
ALTER TABLE dbo.PartitionedTable_Switch
ADD CONSTRAINT CreatedDate_Switch_CHECK CHECK
(CreatedDate >= CONVERT(DATE,'2012-01-01') AND CreatedDate < CONVERT(DATE,'2013-01-01')
AND CreatedDate IS NOT NULL);
GO
N.B. – notice the IS NOT NULL as well 🙂
And now try the switch again: –
ALTER TABLE [dbo].PartitionedTable_Switch
SWITCH
TO [dbo].PartitionedTable
PARTITION 3;
GO
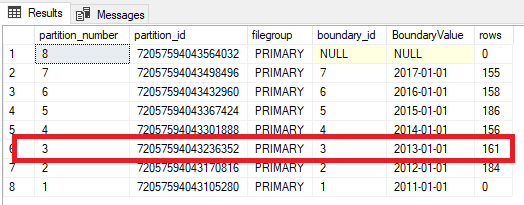
Woo hoo! We’ve got our data back into our main table. So, you don’t have to partition tables that you want to switch data out to, but just be aware that if you do, you need to be able to switch that data back (just in case).
Thanks for reading!