Recently I’ve been delving into Chaos Engineering, reading books, watching videos, listening to podcasts etc. and I find it really intriguing….I mean, it just sounds exciting, right?
CHAOS Engineering!
N.B.- if you want a great resource for how to get into Chaos Engineering, I’d recommend Learning Chaos Engineering by Russ Miles. I’m using concepts and methods from that book to base this (hopefully) series of posts focusing on SQL Server but if you want a more in-depth dive…grab a copy of the book.
OK, before we move onto applying to SQL Server…first, a bit of history.

Back in 2010 Netflix migrated their platform to the cloud. When they did so they decided to adopt a mindset of: –
The best way to avoid failure is to fail constantly
The idea behind this is that if the platform cannot withstand a (semi)controlled outage, how will it react to an uncontrolled outage?
Out of that mindset came Chaos Monkey. A tool that’s designed to randomly terminate instances within their environment. Sounds nuts, right?
This is where Chaos Engineering comes from. So what exactly is it?
Principlesofchaos.org defines Chaos Engineering as: –
Chaos Engineering is the discipline of experimenting on a system in order to build confidence in the system’s capability to withstand turbulent conditions in production.
Chaos Engineering is a practice in which we run experiments against a system to see if it reacts the way we expect it to when it encounters a failure.
We’re not trying to break things here…Chaos Engineering is not breaking things in production.
If I said to my boss that we’re now going to be experiencing an increased amount of outages because, “I AM AN ENGINEER OF CHAOS”, I’d be marched out the front door pretty quickly.
What we’re doing is investigating our systems to see if they will fail when faced with certain conditions.
We don’t even have to touch production with our tests, and to be honest, I’d recommend running in a development or sandbox environment for you first few experiments. As long as the configuration of the SQL instances in those environments mirrors your production servers then you can definitely get some benefit from running chaos experiments in them.
Now, I know what you’re thinking. “Is Chaos Engineering really just a buzz phrase for resilience testing?”.
Well, yep. Resilience testing is pretty much what we’re doing here but hey, Chaos Engineering sounds cooler.
Anyway, moving on….So how can we apply Chaos Engineering to SQL Server?
The first thing we need to do is identify a potential weakness in SQL Server and the best way to do that is by performing a Past Incident Analysis.
Performing a past incident analysis is a great way to start looking for potential weaknesses/failures in your environment. The main reason being, we want to run a Chaos experiment for a condition that is likely to happen. There’s really no point in running an experiment against a perceived failure/weakness that’s never going to happen (or is extremely unlikely) because we want to get some actionable results from these tests.
The end goal here is to increase our confidence in our systems so that we know that they will react as we expect them to when they encounter failure.
So we want to identify an potential failure that’s pretty likely to happen and could potentially have a significant impact.
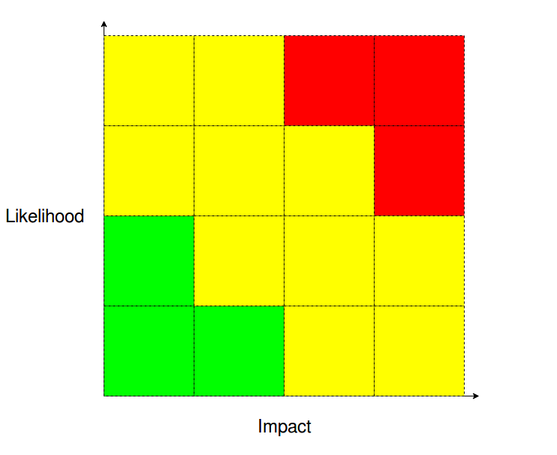
If an incident analysis hasn’t thrown up any candidates another good method is to perform a Likelihood-Impact analysis.
You sit your team down and think about all the ways SQL Server (and the systems around it) can possibly fail.
N.B. – this is really good fun
Then you rank each failure it terms of how likely it is and how impact of an impact it would have. After doing this, you’ll end up with a couple (few?) failures in the red areas of the graphs…you first candidates for your Chaos experiments 🙂
OK, let’s think about some failures…
High Availability
We have a two node cluster hosting an availability group. One test we could run is to failover the availability group to make sure that it’s working as we expect it to. Now we could run
ALTER AVAILABILITY GROUP [NAME] FAILOVER
but that’s a very sanitised way of failing over the AG. How about running a Chaos experiment that shuts down the primary node? Wouldn’t that be a more realistic test of how the AG could fail out in the “wild”?
Monitoring
We don’t just have to test SQL Server…we can test the systems around it. So how about our monitoring systems? Say we run a query against a (test) database that fills the transaction log? When did we get alerted? Did we only get an alert once the log had filled up or did we get preemptive alerts? Did we only get an alert when there was an issue? Is that how we want our monitoring systems to behave? Monitoring systems are vital to our production environments so testing them is an absolute must.
Backups
When was the last time we tested our backups? If we needed to perform a point-in-time restore of a production database right now, would we be able to do it quickly and easily? Or would we be scrambling round getting scripts together? A restore strategy is absolutely something that we want to work when we need it to so we can run experiments to test it on a regular basis (dbatools is awesome for this).
Disaster recovery
OK, let’s go nuclear for the last one. Do we have a DR solution in place? When was the last time the we tested failing over to it? We really don’t want to be enacting our DR strategy for the first time when production is down (seriously).
Those are just a few examples of areas that we can test…there are hundreds of others that can be run. Literally any system or process in production can have a Chaos Engineering experiment run against it.
So now that we’ve identified some failures, we need to pick one and run an experiment…which I’ll discuss in an upcoming post.
Thanks for reading!