One of the best features of Kubernetes is the built-in high availability.
When a node goes offline, all pods on that node are terminated and new ones spun up on a healthy node.
The default time that it takes from a node being reported as not-ready to the pods being moved is 5 minutes.
This really isn’t a problem if you have multiple pods running under a single deployment. The pods on the healthy nodes will handle any requests made whilst the pod(s) on the downed node are waiting to be moved.
But what happens when you only have one pod in a deployment? Say, when you’re running SQL Server in Kubernetes? Five minutes really isn’t an acceptable time for your SQL instance to be offline.
The simplest way to adjust this is to add the following tolerations to your deployment: –
tolerations:
- key: "node.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 10
- key: "node.kubernetes.io/not-ready"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 10
N.B.- You can read more about taints and tolerations in Kubernetes here
This will move any pods in the deployment to a healthy node 10 seconds after a node is reported as either not-ready or unreachable
But what if you wanted to change the default setting across the cluster?
I was trying to work out how to do this last week and the official docs here reference a flag for the controller manager: –
–pod-eviction-timeout duration Default: 5m0s
The grace period for deleting pods on failed nodes.
Great stuff! That’s exactly what I was looking for!
Unfortunately, it seems that this flag no longer works.
The way to set the eviction timeout value now is to set the flags on the api-server.
Now, this is done differently depending on how you installed Kubernetes. I installed this cluster with kubeadm so needed to create a kubeadm-apiserver-update.yaml file: –
apiVersion: kubeadm.k8s.io/v1beta2 kind: ClusterConfiguration kubernetesVersion: v1.18.0 apiServer: extraArgs: enable-admission-plugins: DefaultTolerationSeconds default-not-ready-toleration-seconds: "10" default-unreachable-toleration-seconds: "10"
N.B.- Make sure the kubernetesVersion is correct
And then apply: –
sudo kubeadm init phase control-plane apiserver --config=kubeadm-apiserver-update.yaml
You can verify that the change has been applied by checking the api-server pods in the kube-system namespace (they should refresh) and by checking here: –
cat /etc/kubernetes/manifests/kube-apiserver.yaml
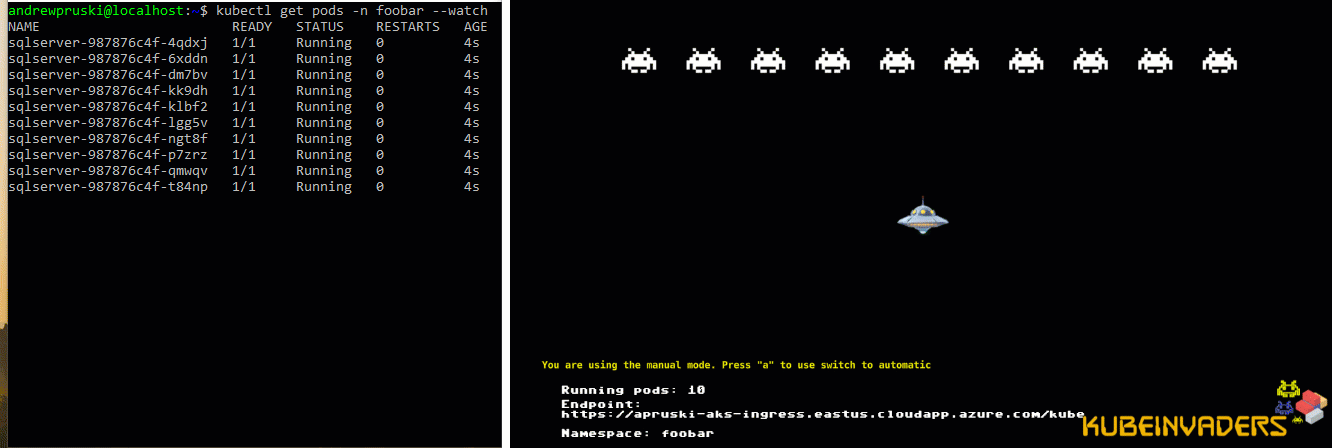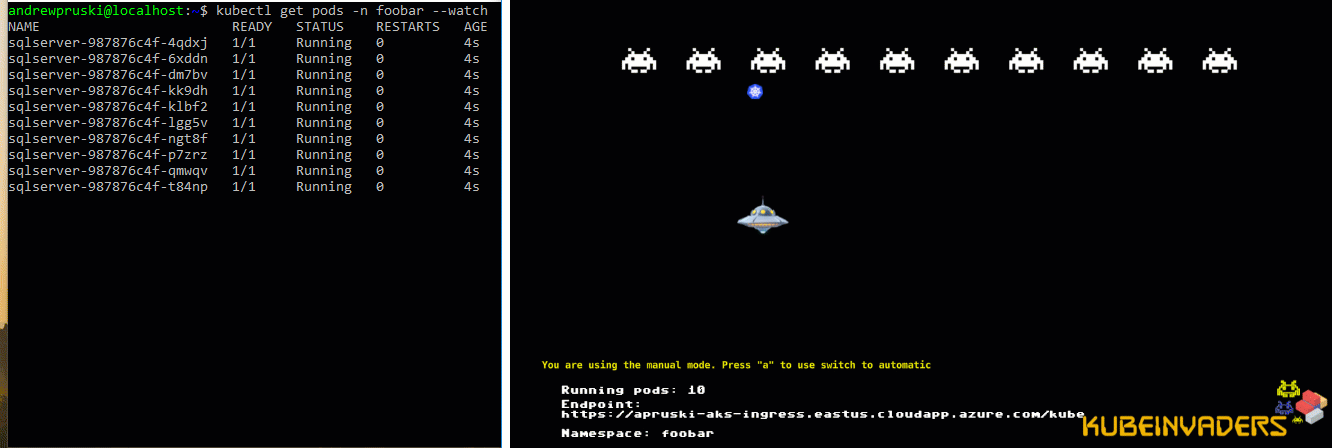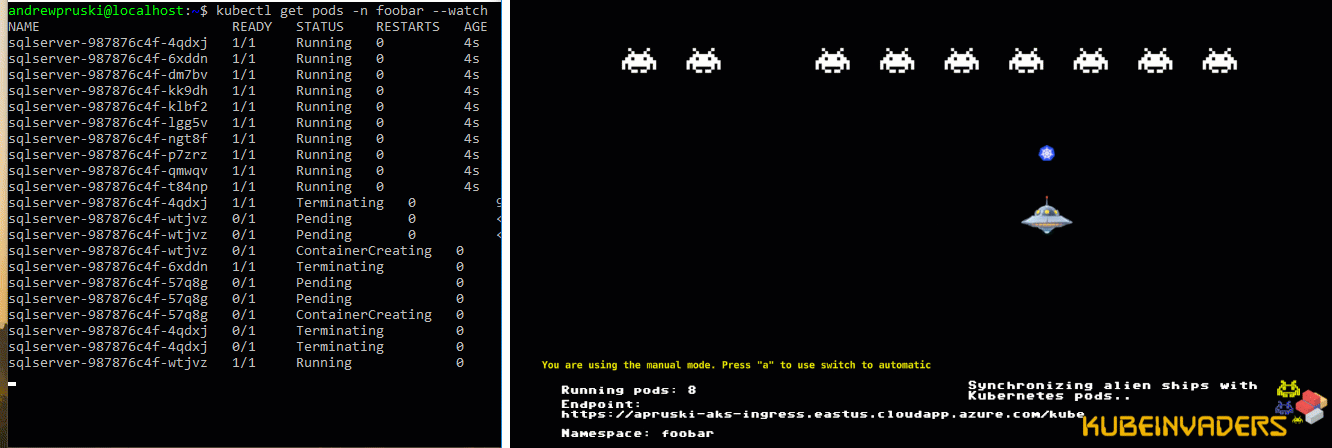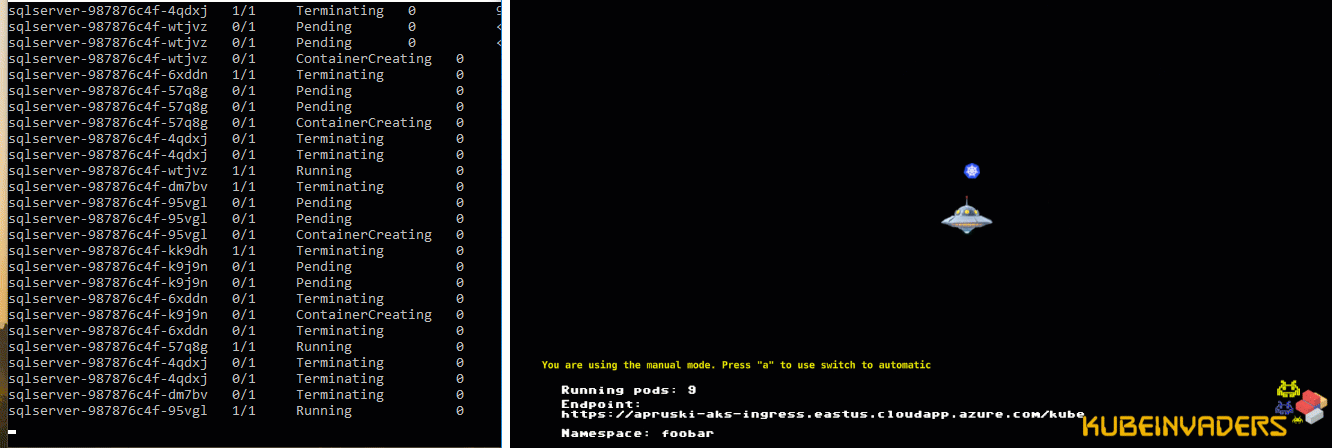
Let’s see it in action! I’ve got one pod running SQL Server in a K8s cluster on node kubernetes-w1. Let’s shut down that node…
Alright, that’s not exactly 10 seconds…there’s a couple of other things going on. But it’s a lot better than 5 mins!
The full deployment yaml that I used is here.
Ok, it is a bit of a contrived test, I’ll admit. The node was shutdown gracefully and I haven’t configured any persistent storage BUT this is still better than having to wait 5 minutes for the pod to be spun up on the healthy node.
N.B.- If you’re working with a managed Kubernetes service, such as AKS or EKS, you won’t be able to do this. You’ll need to add the tolerations to your deployment.
Thanks for reading!