I’ve been running a proof of concept for SQL Server on Kubernetes over the last year or so (ok, probably longer than that…hey, I’m a busy guy 🙂 ) and have come across an issue that has been sort of a show stopper.
UPDATE – This issue has been resolved in Kubernetes version 1.26.
Details are on this github issue: –
https://github.com/kubernetes/kubernetes/issues/65392
And there’s more on the official Kubernetes blog (when a feature called non-graceful node shutdown when into beta): –
https://kubernetes.io/blog/2022/12/16/kubernetes-1-26-non-graceful-node-shutdown-beta/
There are currently no HA solutions for SQL Server running on plain K8s (not discussing Azure Arc here) so my tests have been relying on the in-built HA that Kubernetes provides but there’s a problem.
Let’s see this in action.
First, as we’re running in AKS for this demo, check the storage classes available: –
kubectl get storageclass

We’re going to be using the default storage class for this demo, note the VOLUMEBINDINGMODE is set to WaitForFirstConsumer
Now create the PVC definitions referencing the default storage class: –
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mssql-system
spec:
accessModes:
- ReadWriteOnce
storageClassName: default
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mssql-data
spec:
accessModes:
- ReadWriteOnce
storageClassName: default
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mssql-log
spec:
accessModes:
- ReadWriteOnce
storageClassName: default
resources:
requests:
storage: 1Gi
Save that yaml as sqlserver_pvcs.yaml and deploy: –
kubectl apply -f sqlserver_pvcs.yaml
Confirm the PVCs have been created: –
kubectl get pvc
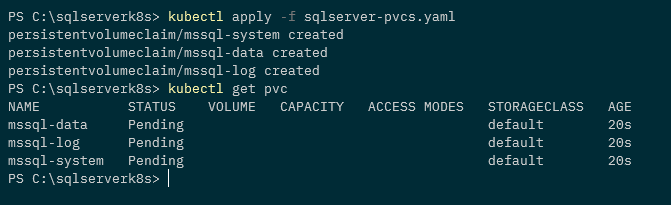
N.B. – The PVCs are in a status of pending as the VOLUMEBINDINGMODE mode of the storage class is set to WaitForFirstConsumer
Now create a sqlserver.yaml file: –
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: sqlserver
name: sqlserver
spec:
replicas: 1
selector:
matchLabels:
app: sqlserver
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: sqlserver
spec:
securityContext:
fsGroup: 10001
containers:
- image: mcr.microsoft.com/mssql/server:2019-CU11-ubuntu-18.04
name: sqlserver
resources: {}
env:
- name: ACCEPT_EULA
value: "Y"
- name: MSSQL_SA_PASSWORD
value: "Testing1122"
volumeMounts:
- name: system
mountPath: /var/opt/mssql
- name: user
mountPath: /var/opt/sqlserver/data
- name: log
mountPath: /var/opt/sqlserver/log
tolerations:
- key: "node.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 10
- key: "node.kubernetes.io/not-ready"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 10
volumes:
- name: system
persistentVolumeClaim:
claimName: mssql-system
- name: user
persistentVolumeClaim:
claimName: mssql-data
- name: log
persistentVolumeClaim:
claimName: mssql-log
status: {}
N.B. – Note the tolerations set for this deployment, if you want to learn more you can check out my blog post here
Deploy that: –
kubectl apply -f sqlserver.yaml
And check that the deployment was successful: –
kubectl get deployments
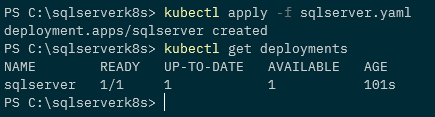
Now the PVCs and corresponding PVs will have been created: –
kubectl get pvc kubectl get pv

OK let’s have a look at the events of the pod: –
kubectl describe pod -l app=sqlserver

So we had a couple of errors from the scheduler initially, (probably) because the PVCs weren’t created in time…but then the attachdetach-controller kicked in and attached the volumes for the pod to use.
Now that the pod is up and confirm the node that the pod is running on: –
kubectl get pods -o wide

OK, shutdown the node in the Azure portal to simulate a node failure: –
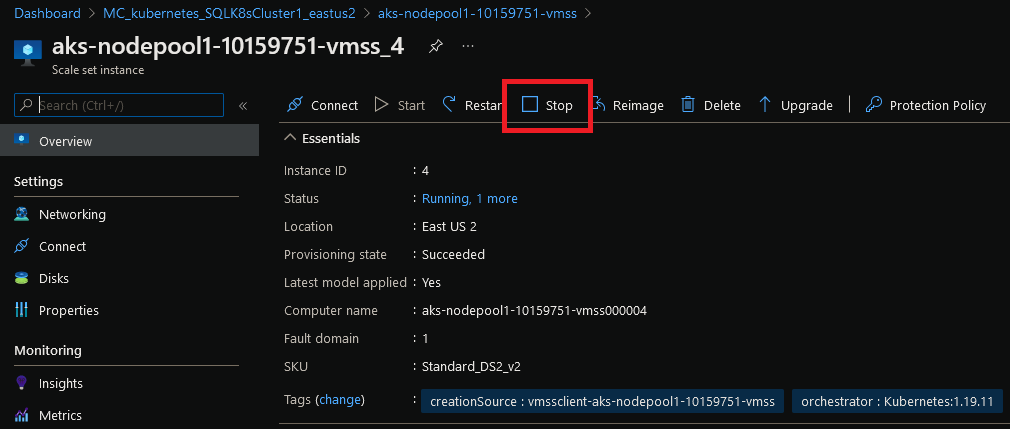
Wait for the node to become unavailable: –
kubectl get nodes --watch
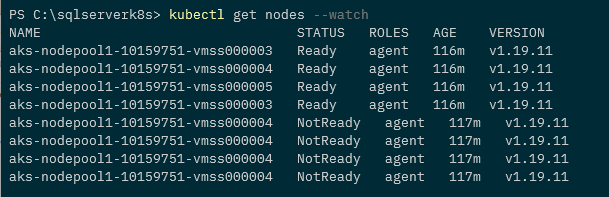
Once the node is reported as unavailable, check the status of the pod. A new one should be spun up on a new, available node:-
kubectl get pods -o wide

The old pod is in a Terminating state, a new one has been created but is in the ContainerCreating state and there it will stay…never coming online.
We can see why if we look at the events of the new pod: –
kubectl describe pod sqlserver-59c78ddc9f-tj9qr

And here’s the issue. The attachdetach-controller cannot move the volumes for the new pod to use as they’re still attached to the old pod.
(EDIT – Technically the volumes are attached to the node but the error reports that the volumes are in use by the old pod)
This is because the node that the old pod is on is in a state of NotReady…so the cluster has no idea of the state of that pod (it’s being reported as terminating but hasn’t been removed completely).
Let’s restart the node: –
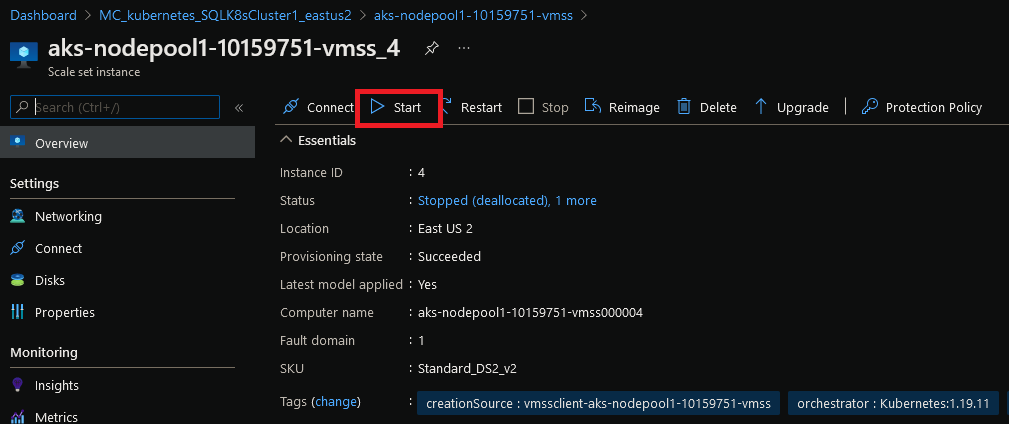
And wait for it to come online: –
kubectl get nodes --watch
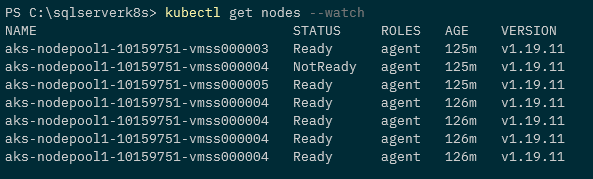
Once the node is online, the old pod will be removed and the new pod will come online: –
kubectl get pods -o wide

Looking at the pod events again: –
kubectl describe pod sqlserver-59c78ddc9f-tj9qr

We can see that once the node came online the attachdetach-controller was able to attach the volumes.
This is an issue as it requires manual intervention for the new pod to come online. Someone has to either bring the node back online or remove it from the cluster completely, not what you want as this will mean extended downtime for SQL Server running in the pod.
So what can we do about this? Well we’ve been looking at a couple of solutions which I’ll cover in upcoming blog posts 🙂
Note, if anyone out there knows how to get around this issue (specifically altering the behaviour of the attachdetach-controller) please get in contact!
Thanks for reading!




























