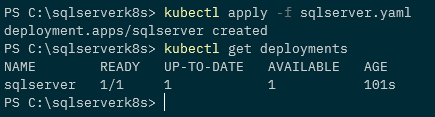
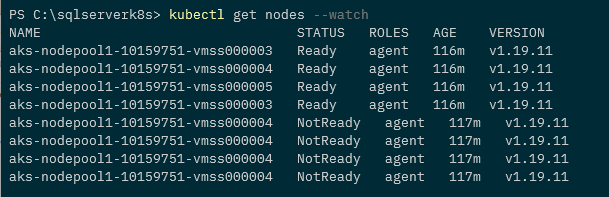
The other day I came across an interesting repo on github, KubeDiagrams.
What this repo does is generate Kubernetes architecture diagrams from Kubernetes manifest files…nice!
Deploying applications to Kubernetes can get complicated fast…especially with stateful applications such as SQL Server.
So having the ability to easily generate diagrams is really helpful…because we all should be documenting everything, right? 🙂
Plus I’m rubbish at creating diagrams!
So let’s have a look at how this works. First, install the dependencies via pip: –
pip install pyyaml pip install diagrams
And install graphviz: –
sudo apt install graphviz
Great, now pull down the repo: –
git clone https://github.com/philippemerle/KubeDiagrams.git
And we’re good to go! So here’s an example manifest file to deploy a SQL Server statefulset to Kubernetes: –
apiVersion: v1
kind: Namespace
metadata:
name: mssql
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: mssql-sc
provisioner: docker.io/hostpath
reclaimPolicy: Delete
volumeBindingMode: Immediate
---
apiVersion: v1
kind: Service
metadata:
name: mssql-headless
namespace: mssql
spec:
clusterIP: None
selector:
name: mssql-pod
ports:
- name: mssql-port
port: 1433
targetPort: 1433
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mssql-statefulset
namespace: mssql
spec:
serviceName: "mssql-headless"
replicas: 1
podManagementPolicy: Parallel
selector:
matchLabels:
name: mssql-pod
template:
metadata:
labels:
name: mssql-pod
spec:
securityContext:
fsGroup: 10001
containers:
- name: mssql-container
image: mcr.microsoft.com/mssql/server:2022-CU16-ubuntu-20.04
ports:
- containerPort: 1433
name: mssql-port
env:
- name: MSSQL_PID
value: "Developer"
- name: ACCEPT_EULA
value: "Y"
- name: MSSQL_AGENT_ENABLED
value: "1"
- name: MSSQL_SA_PASSWORD
value: "Testing1122"
resources:
requests:
memory: "1024Mi"
cpu: "500m"
limits:
memory: "2048Mi"
cpu: "2000m"
volumeMounts:
- name: sqlsystem
mountPath: /var/opt/mssql
- name: sqldata
mountPath: /opt/sqlserver/data
- name: sqllog
mountPath: /opt/sqlserver/log
volumeClaimTemplates:
- metadata:
name: sqlsystem
namespace: mssql
spec:
accessModes:
- ReadWriteOncePod
storageClassName: mssql-sc
resources:
requests:
storage: 25Gi
- metadata:
name: sqldata
namespace: mssql
spec:
accessModes:
- ReadWriteOncePod
storageClassName: mssql-sc
resources:
requests:
storage: 25Gi
- metadata:
name: sqllog
namespace: mssql
spec:
accessModes:
- ReadWriteOncePod
storageClassName: mssql-sc
resources:
requests:
storage: 25Gi
---
apiVersion: v1
kind: Service
metadata:
name: mssql-service
namespace: mssql
spec:
ports:
- name: mssql-ports
port: 1433
targetPort: 1433
selector:
name: mssql-pod
type: LoadBalancer
I’m using Docker Desktop here (hence the provisioner: docker.io/hostpath in the storage class). What this’ll create is a namespace, storage class, headless service for the statefulset, the statefulset itself, three persistent volume claims, and a load balanced service to connect to SQL.
Quite a lot of objects for a simple SQL Server deployment, right? (ahh I know it’s a statefulset, but you know what I mean)
So let’s point KubeDiagrams at the manifest: –
./kube-diagrams mssql-statefulset.yaml
And here’s the output!

Pretty cool, eh?
I noticed a couple of quirks. The docs say it’ll work with any version 3 install of python. I had 3.8 installed but had to upgrade to 3.9.
Also I had to add namespace: mssql to the PVCs in the statefulset, otherwise KubeDiagrams threw a warning: –
Error: ‘sqlsystem/mssql/PersistentVolumeClaim/v1’ resource not found!
Error: ‘sqldata/mssql/PersistentVolumeClaim/v1’ resource not found!
Error: ‘sqllog/mssql/PersistentVolumeClaim/v1’ resource not found
But other than those, it works really well and is a great way to visualise objects in Kubernetes.
Massive thank you to the creator, Philippe Merle!
Thanks for reading!