One of the new options available in SQL Server 2017 is the ability to specify a filegroup when using SELECT..INTO to create a table.
Previous versions would create the new table on the PRIMARY filegroup which isn’t ideal so this is a pretty nifty option imho. Let’s run through a quick demo for which I’m going to restore the AdventureWorks database that’s available here.
The first thing to do once the database has been restored is to set the database to the SQL 2017 compatibility level:-
USE [master]
GO
ALTER DATABASE [AdventureWorks] SET COMPATIBILITY_LEVEL = 140
GO
Then I’m going to add a new filegroup to the database (so that I can create my new table on it): –
USE [master];
GO
ALTER DATABASE [AdventureWorks] ADD FILEGROUP [TempData]
GO
ALTER DATABASE [AdventureWorks] ADD FILE
( NAME = N'AdventureWorks_TempData',
FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\MSSQL\DATA\AdventureWorks_TempData.ndf' ,
SIZE = 8192KB ,
FILEGROWTH = 65536KB ) TO FILEGROUP [TempData]
GO
Now I can run the SELECT…INTO statement using the new ON FILEGROUP option. I’m going to run an example SELECT statement to capture Sales in the UK: –
USE [AdventureWorks];
GO
SELECT c.CustomerID, c.AccountNumber, p.FirstName, p.LastName, p.EmailAddress
INTO dbo.CollectedData ON TempData
FROM Sales.Customer c
INNER JOIN Sales.CustomerPII p ON c.CustomerID = p.CustomerID
INNER JOIN Sales.SalesTerritory t ON p.TerritoryID = t.TerritoryID
WHERE t.Name = 'United Kingdom';
GO
Once that has completed I can check that the new table is on the filegroup that I specified by running: –
SELECT f.name AS [Filegroup]
FROM sys.indexes i
INNER JOIN sys.filegroups f ON i.data_space_id = f.data_space_id
INNER JOIN sys.objects o ON i.object_id = o.object_id
WHERE o.name = 'CollectedData'
GO

Pretty cool huh? So what’s the benefits of this?
Well, this allows us to have a separate filegroup for all user created tables (in this manner). The files behind that filegroup could be on a separate drive allowing you to separate the IO of these processes away from the day-to-day database operations.
What it comes down to is that it gives us more flexibility when working with data and that’s a good thing, right?
Finally, I did have a go a specifying a memory optimised filegroup but unfortunately it’s not supported.
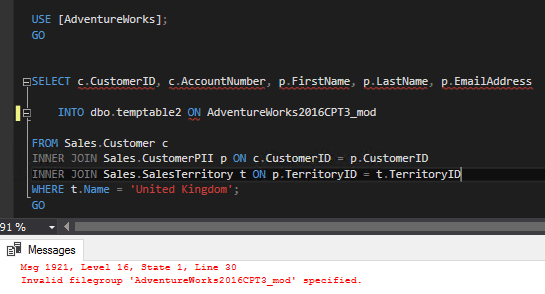
Now that would be really useful as it would be blazingly fast. Hopefully something for a future version?
Thanks for reading!