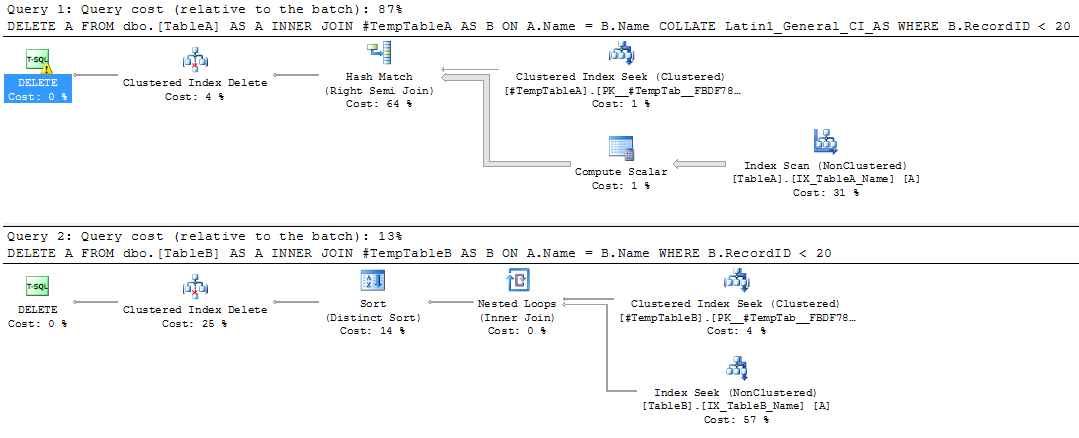
Each time you view a seek/scan operator in an execution plan, you may have noticed that there’s a value for the estimated number of rows and a value for the actual number of rows. Sometimes these values can be fairly similar and sometimes they can be very different.
The estimated number of rows (or cardinality estimate) is very important when SQL is generating a plan to use for your query. It can mean the difference of your query running in milliseconds or minutes.
Quoting from Books Online:-
The query optimizer in SQL Server is cost-based. This means that it selects query plans that have the lowest estimated processing cost to execute. The query optimizer determines the cost of executing a query plan based on two main factors:
• The total number of rows processed at each level of a query plan, referred to as the cardinality of the plan.
• The cost model of the algorithm dictated by the operators used in the query.
The first factor, cardinality, is used as an input parameter of the second factor, the cost model. Therefore, improved cardinality leads to better estimated costs and, in turn, faster execution plans.
So, having an accurate value for the cardinality will allow SQL to generate a more efficient query plan which in turn will improve the performance of the query when executed. But how does the optimizer calculate the cardinality? Knowing how this value is calculated will allow you to write/tune queries more effectively.
I’ve got a few examples that will show the different values calculated in different scenarios. First, create a demo database:-
USE [master];
GO
IF EXISTS(SELECT 1 FROM sys.databases WHERE name = 'EstimatedRowsDemo')
DROP DATABASE [EstimatedRowsDemo];
GO
IF NOT EXISTS(SELECT 1 FROM sys.databases WHERE name = 'EstimatedRowsDemo')
CREATE DATABASE [EstimatedRowsDemo];
GO
Then create a table and insert some data:-
USE [EstimatedRowsDemo];
GO
IF EXISTS(SELECT 1 FROM sys.objects WHERE name = 'DemoTable')
DROP TABLE dbo.DemoTable;
IF NOT EXISTS(SELECT 1 FROM sys.objects WHERE name = 'DemoTable')
CREATE TABLE dbo.DemoTable
(ColA INT,
ColB SYSNAME);
GO
INSERT INTO dbo.DemoTable
(ColA, ColB)
VALUES
(100 , 'VALUE1')
GO 200
INSERT INTO dbo.DemoTable
(ColA, ColB)
VALUES
(200 , 'VALUE2')
GO 500
INSERT INTO dbo.DemoTable
(ColA, ColB)
VALUES
(300 , 'VALUE2')
GO 400
Then create an index on the table:-
CREATE NONCLUSTERED INDEX [IX_DemoTable_ColA] on dbo.[DemoTable](ColA);
GO
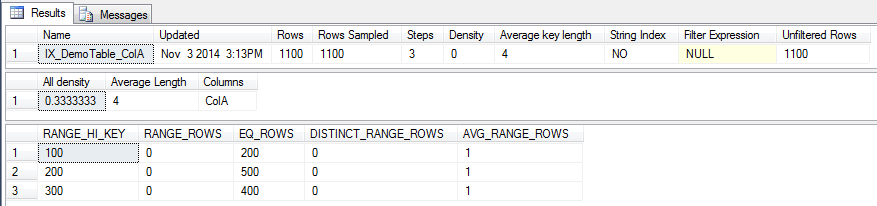
We can now look at the statistics on that index:-
DBCC SHOW_STATISTICS ('dbo.DemoTable','IX_DemoTable_ColA');
GO
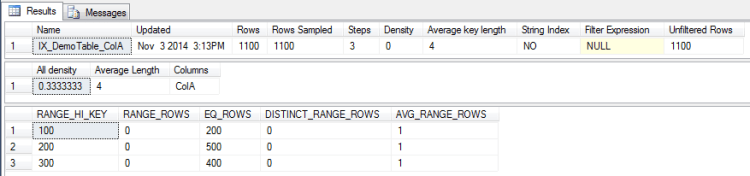
I’m not going to go through what each of the values means, the following article on Books Online explains each value:-
http://msdn.microsoft.com/en-us/library/hh510179.aspx
Now we can start running queries against the table and view the number of estimated rows value that the optimiser generates.
Quick note – All the queries are being run in SQL Server 2014 and will give the same execution plan:-

Remember, it’s the estimated number of rows generated for each one that we are interested in. Also, I’m running the following before each SELECT statement:-
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
Don’t forget to click the ‘Include Actual Execution Plan’ button in SSMS (or hit Ctrl + M) as well.
OK, let’s go.
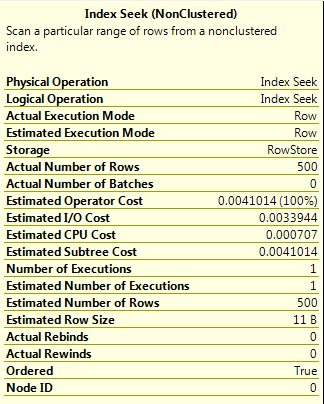
Query A
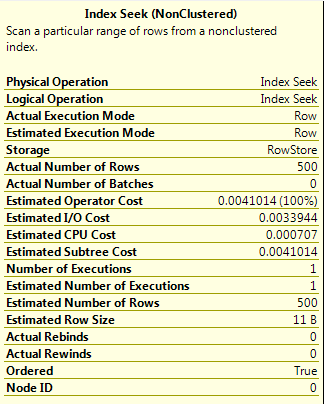
SELECT ColA FROM dbo.[DemoTable] WHERE ColA = 200;
GO
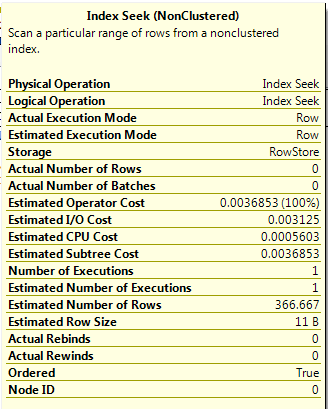
The value 200 corresponds to a RANGE_HI_KEY value in the stats for the index so the value for the EQ_ROWS is used, giving the estimated number of rows as 500.
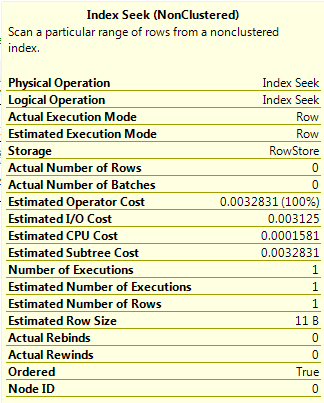
Query B
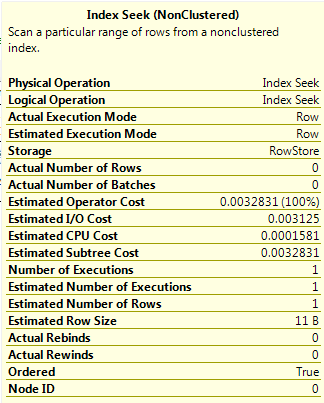
SELECT ColA FROM dbo.[DemoTable] WHERE ColA = 201;
GO
The value 201 is not one of the RANGE_HI_KEY values in the stats so the value for the AVG_RANGE_ROWS in the histogram step where the value would fall is used. This gives an estimated number of rows as 1, a significant difference from Query A.
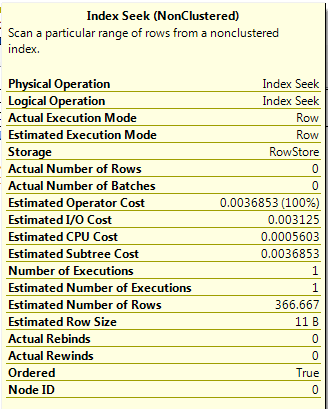
Query C
DECLARE @ParamA INT = 201;
SELECT ColA FROM dbo.[DemoTable] WHERE ColA = @ParamA;
GO
As a parameter is used in this query, the optimiser does not know the value set so the estimated number of rows is calculated as Density * Total Number of Rows (0.3333333 * 1100). This shows that using parameters in queries can drastically affect the estimated number of rows generated.
Query D
DECLARE @ParamA INT = 200;
SELECT ColA FROM dbo.[DemoTable] WHERE ColA > @ParamA;
GO
This query uses a parameter value but with an inequality operator (>). In this situation the estimated number of rows is 30% of the total number of rows in the table.
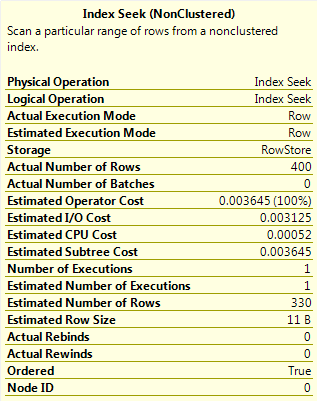
Query E
DECLARE @ParamA INT = 200;
SELECT ColA FROM dbo.[DemoTable] WHERE ColA > @ParamA OPTION(RECOMPILE);
GO
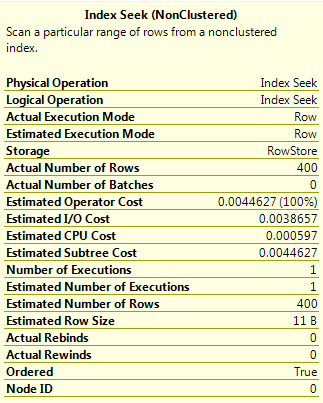
This is the same query as Query D but has OPTION(RECOMPILE) specified. This forces the plan to be compiled with the current value of the parameter, meaning that as the value is a RANGE_HI_KEY, the EQ_ROWS value for that histogram step is used. This gives a value of 400 for the estimated number of rows.
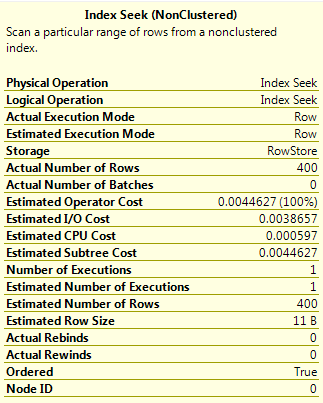
Query F
DECLARE @ParamA INT = 200;
DECLARE @ParamB INT = 300;
SELECT ColA FROM dbo.[DemoTable] WHERE ColA > @ParamA AND ColA < @ParamB
OPTION (QUERYTRACEON 9481);
GO
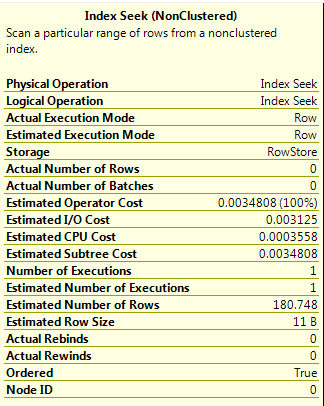
This query has two inequality operators. I specified OPTION (QUERYTRACEON 9481) to force SQL 2014 to use the old cardinality estimator, which will estimate the number of rows as 9% of the total number of rows in the able when two inequality operators are used.

When this query is run in SQL 2014 (using the new cardinality estimator) a different result for the estimated rows is generated. I’m unsure as to how this value is calculated, something that I will investigate in the future but for now it is just something to be aware of as the value is significantly different (180 vs 99).
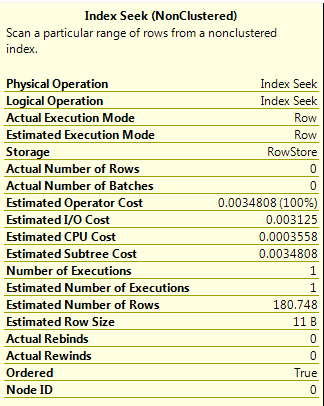
EDIT
Kevan Riley (@KevRiley) contacted me about the new cardinality estimator for SQL 2014 and how it differs from the estimator in 2012.
For multiple predicates the estimator in 2012 used the formula:-
((Estimated number of rows for first predicate) *
(Estimated number of rows for second predicate)) /
Total number of rows
So for this query in 2012: (330 * 330)/1100 = 99
The new estimator in 2014 uses a formula with a process known as exponential backoff:
Selectivity of most selective predicate *
Square root of (selectivity of second most selective predicate) *
Total number of rows
So for this query in 2014: (330/1100) * (SQRT(330/1100)) * 1100 = ~180
Thank you very much Kevan
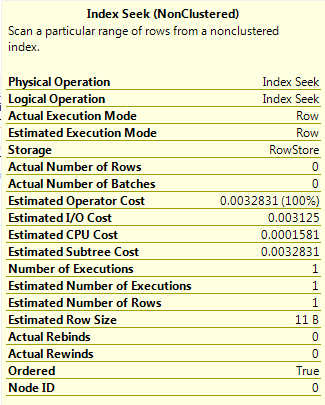
Query G
DECLARE @ParamA INT = 200;
DECLARE @ParamB INT = 300;
SELECT ColA FROM dbo.[DemoTable] WHERE ColA > @ParamA AND ColA < @ParamB OPTION(RECOMPILE);
GO
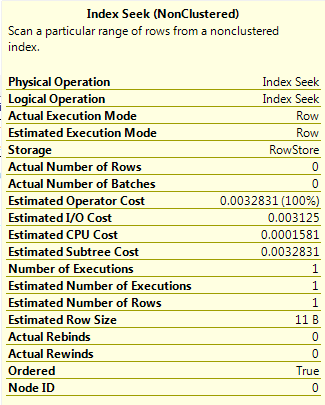
Finally, running the same query as Query F but using OPTION(RECOMPILE). This has the same effect as the result in Query E, the plan is compiled using the current values of the parameters. As there are two values, the optimiser takes a “slice” of the AVG_RANGE_ROWS values from the histogram steps that the parameter values fall across (1 in this simple example).
I hope these examples have shown you how the optimiser calculates the estimated number of rows in different scenarios. Please let me know if you have any feedback in the comments section.
Further information
This post is designed to give a brief introduction into cardinality estimation. There are literally hundreds on articles on the web about this subject, even more so now with the changes made in SQL 2014. Below are articles/posts I referenced to write this post.
Gail Shaw has a good presentation on this subject (which I referenced to write this post), it can be found here:-
http://www.sqlpass.org/24hours/2014/summitpreview/Sessions/SessionDetails.aspx?sid=7279
Paul White on multiple predicates for cardinality estimates:-
http://sqlperformance.com/2014/01/sql-plan/cardinality-estimation-for-multiple-predicates
Fabiano Amorim on getting the statistics used in a cached query plan:-
http://blogfabiano.com/2012/07/03/statistics-used-in-a-cached-query-plan/