A while back I wrote a post about creating a pacemaker cluster to run SQL Server availability group using the new Ubuntu images in Azure.
Recently I had to create another pacemaker cluster, this time on-premises using VMWare virtual machines. The steps to create the pacemaker cluster and deploy an availability group where pretty much the same as in my original post (minus any Azure marlarkey) but one step was different, creating the STONITH resource.
A STONITH resource is needed in a pacemaker cluster as this is what prevents the dreaded split brain scenario…two nodes thinking that they’re the primary node. If the resource detects a failed node in the cluster it’ll restart that node, hopefully allowing it to come up in the correct state.
There are different types of STONITH resources, in my original post I used a fence_azure_arm type, not available to me for my on-premises cluster.
So which type do you use and how do you configure it?
N.B. – This was a three node cluster running Ubuntu 20.04 and I configured it using crmsh
In order to list which types are available, run:-
crm ra list stonith

There are a few ones related to VMWare, I ended up going with the fence_vmware_rest type.
To test the resource before deploying: –
fence_vmware_rest -a <VSPHERE IP ADDRESS> -l <LOGIN> -p <PASSWORD> --ssl-insecure -z -o list | egrep "(<NODE1>|<NODE2>|<NODE3>)" fence_vmware_rest -a <VSPHERE IP ADDRESS> -l <LOGIN> -p <PASSWORD> --ssl-insecure -z -o status -n <NODE1>
Now we can create the resource: –
sudo crm configure primitive fence_vmware stonith:fence_vmware_rest \ params \ ipaddr="<VSPHERE IP ADDRESS>" \ action=reboot \ login="<LOGIN>" \ passwd="<PASSWORD>" \ ssl=1 ssl_insecure=1 \ pcmk_reboot_timeout=900 \ power_timeout=60 \ op monitor \ interval=3600 \ timeout=120
There are a whole load of properties that can be set, to check them out run: –
crm ra info stonith:fence_vmware_rest
We can also configure additional properties: –
sudo crm configure property cluster-recheck-interval=2min sudo crm configure property start-failure-is-fatal=true sudo crm configure property stonith-timeout=900
A good explanation of these properties can be found here.
Now enable the STONITH resource: –
sudo crm configure property stonith-enabled=true
Now that the resource has been created and enabled, confirm the cluster status: –
sudo crm status
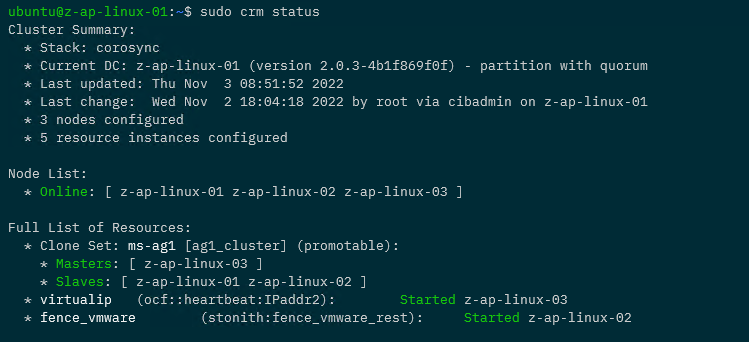
Awesome, we have our STONITH resource up and running in the cluster!
If you want to test the resource, this will fence a node: –
sudo crm node fence <NODE>
So that’s how to deploy a STONITH resource for a pacemaker cluster on VMWare virtual machines. If you want to see the whole process of creating the cluster, the code is available here.
One word of caution, there are a lot of STONITH and cluster properties that can be set…please remember to test your configuration fully before deploying to production!
Thanks for reading!