This post follows on from In-Memory OLTP: Part 3 – Durability & Recovery
In this final post for the #SQLNewBlogger challenge I want to go over another new feature of In-Memory OLTP, natively compiled stored procedures. Natively compiled stored procedures differ from normal stored procedures in that the In-Memory OLTP engine converts the code within the stored procedure to machine code when they are created. This means that no extra compilation to convert t-sql into a set of instructions that can be processed by a CPU needs to be performed when they are executed.
(I’m guessing that as disk IO has been taken out of the picture, Microsoft looked at other ways to improve performance of data operations and the compile time of stored procedures was identified, kinda cool eh?)
Here’s the syntax for creating a natively compiled stored procedure:-
CREATE PROCEDURE dbo.Example
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH
(TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'English')
.
.
.
.
.
.
END
GO
Let’s go over the settings specified in the create statement:-
- NATIVE_COMPLIATION – Does what it says on the tin
- SCHEMABINDING – This prevents the tables accessed being dropped
- EXECUTE AS OWNER – EXECUTE AS CALLER is not supported so a specific execution context must be supplied
- ATOMIC – Everything within the stored procedure is executed as one “block”. Either all the statements within the transaction succeed or will be rolled back
As BEGIN ATOMIC has been specified the following must also be declared:-
- TRANSACTION ISOLATION LEVEL = SNAPSHOT – Only SNAPSHOT, REPEATABLEREAD, and SERIALIZABLE are supported
- LANGUAGE = N’English’ – a language from sys.syslanguages must be declared
Let’s see this in action. Create a database to contain a memory optimised table and stored procedure (code from the previous posts):-
USE [master];
GO
IF EXISTS(SELECT 1 FROM sys.databases WHERE name = 'InMemoryOLTPDemo')
DROP DATABASE [InMemoryOLTPDemo];
GO
IF NOT EXISTS(SELECT 1 FROM sys.databases WHERE name = 'InMemoryOLTPDemo')
BEGIN
CREATE DATABASE [InMemoryOLTPDemo]
ON PRIMARY
(NAME = N'InMemoryOLTPDemo Primary',
FILENAME = N'C:\SQLServer\Data\InMemoryOLTPDemo.MDF',
SIZE = 5MB,
FILEGROWTH = 1MB,
MAXSIZE = UNLIMITED)
LOG ON
(NAME = 'InMemoryOLTPDemo Log',
FILENAME = N'C:\SQLServer\LogInMemoryOLTPDemo_Log.LDF',
SIZE = 5MB,
FILEGROWTH = 1MB,
MAXSIZE = UNLIMITED)
COLLATE Latin1_General_100_BIN2;
END
ALTER DATABASE [InMemoryOLTPDemo] ADD FILEGROUP MemData CONTAINS MEMORY_OPTIMIZED_DATA;
ALTER DATABASE [InMemoryOLTPDemo]
ADD FILE
(NAME = N'InMemoryOLTPDemo Memory Optimised',
FILENAME = N'C:\SQLServer\Data\InMemoryOLTPDemo_MemOp')
TO FILEGROUP MemData;
GO
Set up the memory optimised table:-
USE [InMemoryOLTPDemo];
GO
IF EXISTS(SELECT 1 FROM sys.tables WHERE name = 'EmployeeTableInMemory')
DROP TABLE [EmployeeTableInMemory];
GO
IF NOT EXISTS(SELECT 1 FROM sys.tables WHERE name = 'EmployeeTableInMemory')
CREATE TABLE [EmployeeTableInMemory]
(EmployeeID INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1024),
Department SYSNAME NOT NULL INDEX IX_Department NONCLUSTERED HASH WITH (BUCKET_COUNT = 1024),
FirstName SYSNAME,
LastName SYSNAME,
DateCreated DATE)
WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA);
GO
SET NOCOUNT ON;
DECLARE @Counter INT = 1;
WHILE @Counter < 100000
BEGIN
INSERT INTO dbo.EmployeeTableInMemory
(EmployeeID, Department, FirstName, LastName, DateCreated)
VALUES
(@Counter, 'TEST', 'TestForename','TestSurname',CONVERT(DATE,GETDATE()))
SET @Counter = @Counter + 1;
END
GO
Now, create a normal stored procedure and a memory optimised one:-
CREATE PROCEDURE dbo.TestNormal
AS
SELECT E1.EmployeeID, E1.Department, E1.FirstName, E1.LastName, E1.DateCreated
FROM dbo.EmployeeTableInMemory E1
INNER JOIN dbo.EmployeeTableInMemory E2 ON E1.EmployeeID = E2.EmployeeID
INNER JOIN dbo.EmployeeTableInMemory E3 ON E1.EmployeeID = E3.EmployeeID
INNER JOIN dbo.EmployeeTableInMemory E4 ON E1.EmployeeID = E4.EmployeeID
INNER JOIN dbo.EmployeeTableInMemory E5 ON E1.EmployeeID = E5.EmployeeID
INNER JOIN dbo.EmployeeTableInMemory E6 ON E1.EmployeeID = E6.EmployeeID
INNER JOIN dbo.EmployeeTableInMemory E7 ON E1.EmployeeID = E7.EmployeeID
INNER JOIN dbo.EmployeeTableInMemory E8 ON E1.EmployeeID = E8.EmployeeID
INNER JOIN dbo.EmployeeTableInMemory E9 ON E1.EmployeeID = E9.EmployeeID
INNER JOIN dbo.EmployeeTableInMemory E10 ON E1.EmployeeID = E10.EmployeeID
ORDER BY E10.EmployeeID DESC OPTION(RECOMPILE)
GO
CREATE PROCEDURE dbo.TestNative
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH
(TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'English')
SELECT E1.EmployeeID, E1.Department, E1.FirstName, E1.LastName, E1.DateCreated
FROM dbo.EmployeeTableInMemory E1
INNER JOIN dbo.EmployeeTableInMemory E2 ON E1.EmployeeID = E2.EmployeeID
INNER JOIN dbo.EmployeeTableInMemory E3 ON E1.EmployeeID = E3.EmployeeID
INNER JOIN dbo.EmployeeTableInMemory E4 ON E1.EmployeeID = E4.EmployeeID
INNER JOIN dbo.EmployeeTableInMemory E5 ON E1.EmployeeID = E5.EmployeeID
INNER JOIN dbo.EmployeeTableInMemory E6 ON E1.EmployeeID = E6.EmployeeID
INNER JOIN dbo.EmployeeTableInMemory E7 ON E1.EmployeeID = E7.EmployeeID
INNER JOIN dbo.EmployeeTableInMemory E8 ON E1.EmployeeID = E8.EmployeeID
INNER JOIN dbo.EmployeeTableInMemory E9 ON E1.EmployeeID = E9.EmployeeID
INNER JOIN dbo.EmployeeTableInMemory E10 ON E1.EmployeeID = E10.EmployeeID
ORDER BY E10.EmployeeID DESC
END
GO
N.B. – These are horrible stored procs, I know. They’re just for demo purposes. I’ve included OPTION(RECOMPILE) in the normal stored proc so that you can re-run when testing to see the differences each time (otherwise the plan will be cached).
Now run each one with STATISTICS TIME ON:-
SET STATISTICS TIME ON; EXEC dbo.TestNormal; GO

SET STATISTICS TIME ON; EXEC dbo.TestNative; GO
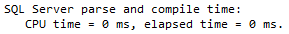
You can see that the natively compiled stored procedure never has any time registered for parse and compile. This is because it was compiled when it was created, meaning that if the procedure has any parameters they are not taken into consideration. All natively compiled stored procedures can be thought of as being optimised for unknown.
In addition, you’re not going to be able to see the execution plan when the stored procedure is executed. Try including the actual execution plan when running the code above. Querying sys.procedures will also not show any clues that the procedure is natively compiled, you’ll have to remember which stored procedures are natively compiled or you’re going to have real fun when investigating any performance issues!
So when should you use natively compiled stored procedures? As with many (most???) things with SQL Server, it depends. There are limitations to what you can do with them, they are designed for OLTP operations that are frequently called which need to be blazingly fast. A full list of the supported constructs for natively compiled stored procedures can be found here. My advice would be take every situation on a case by case basis and test to death but it’s worth remembering that they can only access memory optimised tables and that like those tables, they cannot be altered once created (you have to drop and re-create, feasible on a busy OLTP system?).
So that’s it! I’ve really enjoying writing this series of posts. Thanks very much for reading!
Further Reading
Creating Natively Compiled Stored Procedures – Microsoft
Best Practices for Calling Natively Compiled Stored Procedures