I have recently seen some “bad plans” being generated by the optimiser and from investigation, the cause came down to the fact that the collation of the database where the queries were running was different to the tempdb collation.
Consider this situation, you have a stored procedure which collects various records and stores them in a temporary table. This temporary table is then used as a reference to delete records from another table in the database. This is a bit of a contrived example, but I just want to show you the impact differing collations can have.
N.B. – I’m running this in SQL Server 2012
First I’ll create a database with a different collation to the tempdb (the tempdb collation on my local instance is Latin1_General_CI_AS):-
CREATE DATABASE [CollationConflict] COLLATE SQL_Latin1_General_CP1_CI_AS;
Then I’ll create two tables in the database, populate them with data and create some nonclustered indexes.
Here’s the first table in the database:-
USE [CollationConflict];
GO
SET NOCOUNT ON;
IF EXISTS(SELECT 1 FROM sys.objects WHERE name = 'TableA')
DROP TABLE dbo.[TableA];
GO
IF NOT EXISTS(SELECT 1 FROM sys.objects WHERE name = 'TableA')
CREATE TABLE dbo.[TableA]
(RecordID INT IDENTITY(1,1) PRIMARY KEY,
Name VARCHAR(10));
GO
DECLARE @Counter INT = 0;
DECLARE @Value CHAR(10) = 'TEST';
WHILE @Counter <= 50000
BEGIN
SET @Value = 'TEST' + CONVERT(VARCHAR(4),@Counter)
INSERT INTO dbo.[TableA]
(Name)
VALUES
(@Value);
SET @Counter = @Counter + 1;
END
CREATE NONCLUSTERED INDEX [IX_TableA_Name] ON dbo.[TableA](NAME);
GO
And here’s the second table:-
IF EXISTS(SELECT 1 FROM sys.objects WHERE name = 'TableB')
DROP TABLE dbo.[TableB];
GO
IF NOT EXISTS(SELECT 1 FROM sys.objects WHERE name = 'TableB')
CREATE TABLE dbo.[TableB]
(RecordID INT IDENTITY(1,1) PRIMARY KEY,
Name VARCHAR(10));
GO
DECLARE @Counter INT = 0;
DECLARE @Value CHAR(10) = 'TEST';
WHILE @Counter <= 50000
BEGIN
SET @Value = 'TEST' + CONVERT(VARCHAR(4),@Counter)
INSERT INTO dbo.[TableB]
(Name)
VALUES
(@Value);
SET @Counter = @Counter + 1;
END
CREATE NONCLUSTERED INDEX [IX_TableB_Name] ON dbo.[TableB](NAME);
GO
To show the difference in plan’s generated, I’ll now create two temporary tables. The first one will use the same collation as tempdb but the second will be created with a different collation explicitly set.
Here’s the first temporary table using tempdb’s collation:-
CREATE TABLE #TempTableA
(RecordID INT IDENTITY(1,1) PRIMARY KEY,
Name VARCHAR(10));
DECLARE @Counter INT = 0;
DECLARE @Value CHAR(10) = 'TEST';
WHILE @Counter <= 500
BEGIN
SET @Value = 'TEST' + CONVERT(VARCHAR(4),@Counter)
INSERT INTO #TempTableA
(Name)
VALUES
(@Value);
SET @Counter = @Counter + 1;
END
CREATE NONCLUSTERED INDEX [IX_TempTableA_Name] ON #TempTableA(NAME);
GO
Here’s the second temporary table using same collation as the user database:-
CREATE TABLE #TempTableB
(RecordID INT IDENTITY(1,1) PRIMARY KEY,
Name VARCHAR(10) COLLATE SQL_Latin1_General_CP1_CI_AS);
DECLARE @Counter INT = 0;
DECLARE @Value CHAR(10) = 'TEST';
WHILE @Counter < 500
BEGIN
SET @Value = 'TEST' + CONVERT(VARCHAR(4),@Counter)
INSERT INTO #TempTableB
(Name)
VALUES
(@Value);
SET @Counter = @Counter + 1;
END
CREATE NONCLUSTERED INDEX [IX_TempTableB_Name] ON #TempTableB(NAME);
GO
Now I’m going to run two separate SQL statements which will reference the temp tables. The statements will perform the exact same operation, deleting a set of records from the main tables based on the records in the temp tables.
The only difference is that the COLLATE option is specified in the first (otherwise an error will be generated):-
DELETE A FROM dbo.[TableA] AS A INNER JOIN #TempTableA AS B ON A.Name = B.Name COLLATE Latin1_General_CI_AS WHERE B.RecordID < 20; GO DELETE A FROM dbo.[TableB] AS A INNER JOIN #TempTableB AS B ON A.Name = B.Name WHERE B.RecordID < 20; GO
The DELETE statements will generate the following plans when executed:-
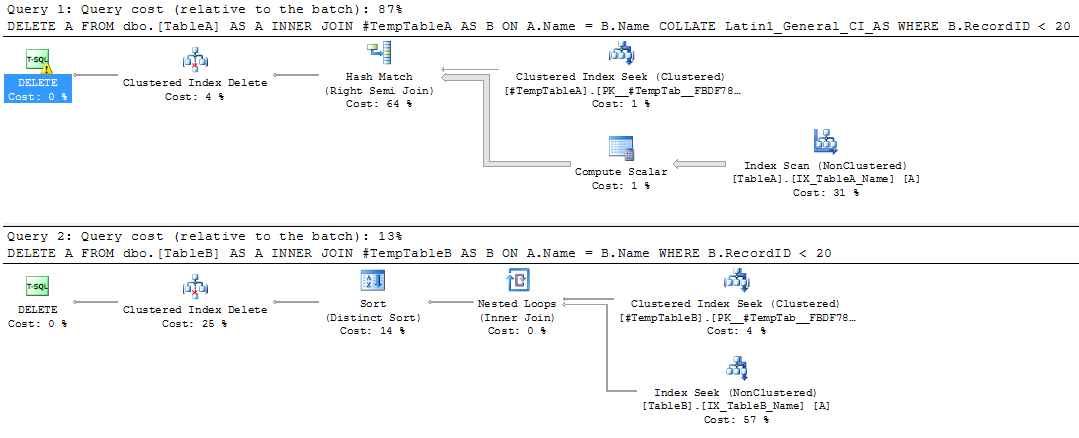
The first query is scanning the nonclustered index. The properties of the DELETE operator show why:-

SQL is performing an implicit conversion, even though the COLLATE option was specified in the join. This is causing the nonclustered index scan. The impact of this can be seen by comparing the properties of the scan vs the seek in the second plan:-

The scan is reading all the records in the table, simply because of the implicit conversion!
So, if your user databases have a different collation than your tempdb ensure that you specify the correct collation when creating your temporary tables. Or just make sure your databases have the same collation as your SQL instance!
