One of the features I’ve been interested in that’s coming with SQL Server 2016 is the stretched database. The ability to “stretch” individual tables in a database into the cloud seems really cool and could help organisations easily archive their data.
There’s a full guide to stretch databases in SQL 2016 Books Online but I’d like to go through a quick setup.
Prerequisites – An Azure account (uh huh) and if you’re installing on a server, you’ll have to add the Azure portal to the list of trusted sites and enable javascript.
First thing to do is enable the SQL instance to host stretched databases:-
EXEC sp_configure 'remote data archive' , '1';
RECONFIGURE;
Now create a database:-
USE [master];
GO
IF NOT EXISTS(SELECT TOP 1 1 FROM sys.databases WHERE name = 'StretchedDatabase')
CREATE DATABASE [StretchDatabase];
GO
Then create a table that will be “stretched”:-
USE [StretchDatabase];
GO
IF NOT EXISTS(SELECT TOP 1 1 FROM sys.objects WHERE name = 'StretchTable')
CREATE TABLE [StretchTable]
(PkID INT IDENTITY(1,1) PRIMARY KEY,
FirstName SYSNAME,
CreatedDate DATETIME);
GO
Ok, so now we connect to our Azure account and setup the stretch. I’m sure there’s a way to do this in powershell but as this is my first time I’m going to use the GUI *gasp*. Right click on the database and go to Tasks > Enable Database for Stretch:-

Enter your Azure login details:-
Ensure you’re using the right subscription (I’ve only got one but you may have a personal & work account):-
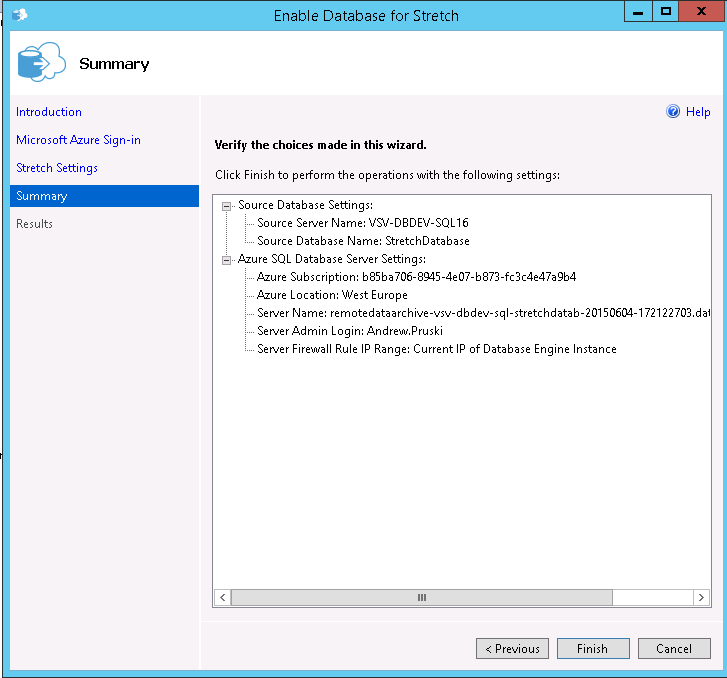
Pick a location for the stretched data to residue in and a login/password. You’ll need to make a note of the login/password for future use when working on the Azure blob (think backup/restore). Also I kept the defaults for the firewall rules but you may want to change them:-

Review the details displayed and click “Finish” (note that there’s no option to script this):-
If all goes well you should see:-

And you can verify that the stretch is setup and connected by looking at the newly created linked server:-

There will also be a new database created in your Azure account:-

That’s it! The database is setup to be have tables stretched into Azure. Now we need to enable the table we created to be stretched:-
USE [StretchDatabase];
GO
ALTER TABLE [StretchTable]
ENABLE REMOTE_DATA_ARCHIVE WITH ( MIGRATION_STATE = ON );
GO
OK, so let’s pump a load of data into the stretched table:-
INSERT INTO dbo.StretchTable
(FirstName,CreatedDate)
VALUES
('TEST',GETDATE());
GO 100
There’s a new DMV in SQL 2016 to allow us to see details of the data that has been migrated to Azure:-
SELECT * FROM sys.dm_db_rda_migration_status;

The new DMV is documented here
As you can see, all the rows that we inserted into the table have been migrated into Azure. I have to admit, I didn’t think this is how the stretch technology would work. For some reason (and I have no basis for thinking this), I thought there would be settings to say only migrate data in the table based on certain conditions would be stretched up to Azure. Being able to set conditions on stretched tables to control how data is migrated is definitely something I’d like to see Microsoft bring in but for now this technology could be very useful in moving old archives tables out of local storage and into the cloud.
But what happens when a database containing a stretched table is restored from backup? Let’s give it a go, so backup the database:-
USE [master];
GO
BACKUP DATABASE [StretchDatabase]
TO DISK = N'C:\SQLServer\Backups\StretchDatabase.BAK'
WITH STATS = 5;
GO
And then immediately restore it:-
RESTORE DATABASE [StretchDatabase]
FROM DISK = N'C:\SQLServer\Backups\StretchDatabase.BAK'
WITH REPLACE, RECOVERY, STATS = 5;
GO
Now query the stretched table:-
USE [StretchDatabase];
GO
SELECT * FROM dbo.StretchTable;
GO
What?! No rows! This happens because the stretched table needs to be reauthorised, remember that login & password you created earlier? You’ll need to use those when executing a new stored procedure sys.sp_reauthorize_remote_data_archive
EXEC sys.sp_reauthorize_remote_data_archive
@azure_username = N'YOUR USERNAME',
@azure_password = N'YOUR PASSWORD';
GO
Now try querying the table again:-
SELECT * FROM dbo.StretchTable;
GO
Rows! The table has reconnected with Azure and the query can return the rows. This step will need to be added to any backup/restore strategy that you put in place. Thankfully you’ll only have to do it once as it’s not table specific. Finally, let’s have a look at the query plan that is generated when querying tables that have been stretched. I’m going to use another new feature in SQL 2016, live query statistics. This couldn’t be easier to use, just click on the new button in SSMS 2016 next to the button that includes the actual execution plan and off you go:-
SELECT * FROM dbo.StretchTable;

In the above GIF you can see the new remote query operator on the right. The live query statistics feature also shows that this is the only source of the data, with the table in the data not returning any rows at all. This is due to the fact that we have not inserted any more rows into the table, if the table was “live” we would see both the table and the remote query operator returning rows and then being combined by the concatenation operator before the select.















