I’ve been playing around with partitioning quite a lot recently and wanted to write a quick post about how it can help you out in a DR situation.
Partitioning is mainly for increasing the manageability of your data but it also has other benefits, one of them being giving you the ability to split a single table across multiple filegroups. This will allow you to keep your current data in one filegroup and, let’s call it historical data, in another. In a DR situation, if you need to bring your current data online quickly and worry about the rest later, this can really help you out.
So let’s run through a quick example.First, create a database:-
CREATE DATABASE [PartitioningDemo]
ON PRIMARY
(NAME = N'PartitionDemo', FILENAME = N'C:\SQLServer\SQLData\PartitionDemo.mdf', SIZE = 51200KB, MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB),
FILEGROUP [DATA]
(NAME = N'DATA', FILENAME = N'C:\SQLServer\SQLData\DATA.ndf', SIZE = 51200KB, MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB ),
FILEGROUP [ARCHIVE]
(NAME = N'ARCHIVE', FILENAME = N'C:\SQLServer\SQLData\ARCHIVE.NDF', SIZE = 51200KB, MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB )
LOG ON
(NAME = N'PartitionDemo_log', FILENAME = N'C:\SQLServer\SQLLog\PartitionDemo_log.ldf', SIZE = 20480KB, MAXSIZE = 2048GB, FILEGROWTH = 512KB)
GO
This database has three filgroups. The PRIMARY (as always), DATA and an ARCHIVE filegroup. What this demo is going to show you is how to bring the PRIMARY and DATA filegroups online first and then bring the ARCHIVE filegroup online afterwards.
So now let’s create a partition scheme and function:-
USE [PartitioningDemo];
GO
CREATE PARTITION FUNCTION PF_PartitionedTable(DATE)
AS RANGE RIGHT
FOR VALUES ('2014-01-01','2015-01-01','2016-01-01');
GO
CREATE PARTITION SCHEME PS_PartitionedTable
AS PARTITION PF_PartitionedTable
TO ([ARCHIVE],[ARCHIVE],[DATA],[DATA]);
GO
The table we’re going to build will be partitioned by year, two partitions on the ARCHIVE group and two on the DATA filegroup.
So let’s create the table (and its clustered index): –
CREATE TABLE dbo.PartitionedTable
(PKID INT IDENTITY(1,1),
ColA VARCHAR(10),
ColB VARCHAR(10),
CreatedDate DATE)
ON PS_PartitionedTable(CreatedDate);
CREATE UNIQUE CLUSTERED INDEX [IX_CreatedDate_PartitionedTable] ON dbo.PartitionedTable
(CreatedDate,PKID)
ON PS_PartitionedTable(CreatedDate);
GO
Now insert some data: –
SET NOCOUNT ON;
INSERT INTO dbo.PartitionedTable
(ColA,ColB,CreatedDate)
VALUES
(REPLICATE('A',10),REPLICATE('A',10),'2013-02-01');
GO 1000
INSERT INTO dbo.PartitionedTable
(ColA,ColB,CreatedDate)
VALUES
(REPLICATE('A',10),REPLICATE('A',10),'2014-02-01');
GO 1000
INSERT INTO dbo.PartitionedTable
(ColA,ColB,CreatedDate)
VALUES
(REPLICATE('A',10),REPLICATE('A',10),'2015-02-01');
GO 1000
INSERT INTO dbo.PartitionedTable
(ColA,ColB,CreatedDate)
VALUES
(REPLICATE('A',10),REPLICATE('A',10),'2016-02-01');
GO 1000
Let’s quickly check the data in the partitions:-
SELECT
t.name AS TableName, i.name AS IndexName, p.partition_number, p.partition_id,
--i.data_space_id, f.function_id, f.type_desc,
fg.name AS [filegroup],
r.boundary_id, r.value AS BoundaryValue, p.rows
--,r.*
FROM
sys.tables AS t
INNER JOIN
sys.indexes AS i ON t.object_id = i.object_id
INNER JOIN
sys.partitions AS p ON i.object_id = p.object_id AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON a.container_id = p.hobt_id
INNER JOIN
sys.filegroups fg ON fg.data_space_id = a.data_space_id
INNER JOIN
sys.partition_schemes AS s ON i.data_space_id = s.data_space_id
INNER JOIN
sys.partition_functions AS f ON s.function_id = f.function_id
LEFT OUTER JOIN
sys.partition_range_values AS r ON f.function_id = r.function_id
AND r.boundary_id = p.partition_number
WHERE
t.name = 'PartitionedTable'
AND
i.type <= 1
AND
a.type = 1 --in row data only
ORDER BY p.partition_number DESC;

So both filegroups have 2000 rows in them. Now let’s perform a filegroup restore, bringing the PRIMARY & DATA filegroups online first.
Take a full and log backup of the database:-
USE [master];
GO
--FULL DATABASE BACKUP
BACKUP DATABASE [PartitioningDemo]
TO DISK = 'C:\SQLServer\Backups\PartitioningDemoFullBackup.bak'
WITH INIT
GO
--LOG BACKUP
BACKUP LOG [PartitioningDemo]
TO DISK = N'C:\SQLServer\Backups\PartitioningDemoLogBackup.trn'
WITH NO_TRUNCATE, INIT
GO
OK, now we’re simulating a problem, first take a tail log backup:-
BACKUP LOG [PartitioningDemo]
TO DISK = N'C:\SQLServer\Backups\PartitioningDemoTailLogBackup.trn'
WITH INIT, NORECOVERY
GO
And now we’re going to perform a filegroup restore of the PRIMARY and DATA filegroups:-
--PRIMARY filegroup
RESTORE DATABASE [PartitioningDemo]
FILEGROUP = 'PRIMARY'
FROM DISK = 'C:\SQLServer\Backups\PartitioningDemoFullBackup.bak'
WITH
REPLACE, PARTIAL, NORECOVERY;
GO
--DATA filegroup
RESTORE DATABASE [PartitioningDemo]
FILEGROUP = 'DATA'
FROM DISK = 'C:\SQLServer\Backups\PartitioningDemoFullBackup.bak'
WITH
REPLACE, PARTIAL, NORECOVERY;
GO
--Restore transaction log & tail log backups
RESTORE LOG [PartitioningDemo] FROM DISK = N'C:\SQLServer\Backups\PartitioningDemoLogBackup.trn' WITH NORECOVERY;
RESTORE LOG [PartitioningDemo] FROM DISK = N'C:\SQLServer\Backups\PartitioningDemoTailLogBackup.trn' WITH RECOVERY;
GO
Now we can query the table:-
SELECT COUNT(*) FROM [PartitioningDemo].dbo.[PartitionedTable]
WHERE CreatedDate > CONVERT(DATE,'2015-01-01')
GO
--Check access to archive data
SELECT COUNT(*) FROM [PartitioningDemo].dbo.[PartitionedTable]
WHERE CreatedDate < CONVERT(DATE,'2015-01-01')
GO
First query will run fine but the second will generate an error:-

So we still have to restore the ARCHIVE filegroup:-
--Restore ARCHIVE filegroup
RESTORE DATABASE [PartitioningDemo]
FILEGROUP = 'ARCHIVE'
FROM DISK = 'C:\SQLServer\Backups\PartitioningDemoFullBackup.bak'
WITH
NORECOVERY;
GO
--Restore transaction log & tail log backups
RESTORE LOG [PartitioningDemo] FROM DISK = N'C:\SQLServer\Backups\PartitioningDemoLogBackup.trn' WITH NORECOVERY;
RESTORE LOG [PartitioningDemo] FROM DISK = N'C:\SQLServer\Backups\PartitioningDemoTailLogBackup.trn' WITH NORECOVERY;
GO
Bring the database fully online:-
RESTORE DATABASE [PartitioningDemo] WITH RECOVERY;
GO
And re-run the queries against the table:-
SELECT COUNT(*) FROM [PartitioningDemo].dbo.[PartitionedTable]
WHERE CreatedDate > CONVERT(DATE,'2015-01-01')
GO
--Check access to archive data
SELECT COUNT(*) FROM [PartitioningDemo].dbo.[PartitionedTable]
WHERE CreatedDate < CONVERT(DATE,'2015-01-01')
GO
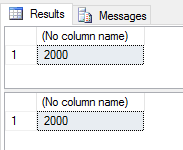
Now both queries will return results:-
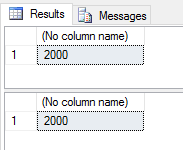
Neat huh? You can see that in a DR situation, if you have a correct partitioning and filegroup strategy in place, you can reduce the amount of time it will take to bring your current data online.
More about filegroup restores: –
https://msdn.microsoft.com/en-ie/library/aa337540.aspx